




Hadoop 分為 1.X 和 2.X 兩個版本,兩個版本互不相容。2.X 在數據處理速度和擴展性上都有大幅度的提升。1.X 跟 2. X最大的差別在於以下兩點,第一,2.X 的 NameNode 改為可以以群集的方式部署,即是說使用者可以建立多個 NameNode,即使一個 NameNode 發生故障亦不會對整個系統作出影響,相比起 1.X 只能建立一個 NameNode 和 Secondary NameNode,且 Secondary NameNode 備份數據時會存在一定的延遲,Hadoop 2.X 大大提升了整個系統的高可用性。
其次,Hadoop 2.X 加入了全新的 YARN 框架。在新的框架之下,原先的 JobTrackerc 分拆成為ApplicationMaster 和 ResourceManager 兩個獨立組件,本次將會使用的是 Hadoop 2.7.2。
在如圖 4 所示,以 root 身份登入三台虛擬機,並且下達【useradd -m hadoop】命令創建一個 Hadoop 帳號用以處理Hadoop的事務,您也可直接以 root 帳號處理。並接著如圖 5 所示下達【passwd hadoop】命令為 Hadoop 帳號設置登入密碼,因方便示範原故這次以 1234 作為密碼。
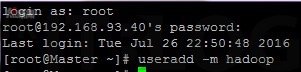
圖 4 建立 Hadoop 帳號
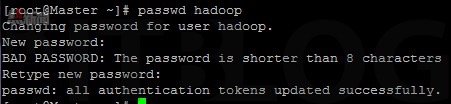
圖 5 建立 Hadoop 帳號密碼
在如圖 6 所示,為方便往後安裝和管理 Hadoop,我們先賦予 Hadoop 帳號管理員權限。本次使用 sed 指令下達【sed -I ‘99 i hadoop ALL=(ALL) ALL’/etc/sudoers】命令直接把 Hadoop 新增至管理員名單,您也可以使用 visudo 指令,之後在第 98 行插入“hadoop ALL=(ALL)”,意即賦予 Hadoop 帳號全部權限。並接著如圖 7 所示,以 Hadoop 身份登入三台虛擬機,並且下達【sudo yum -y update】命令更新系統。

圖 6 設定 Hadoop 帳號為全部權限

圖 7 更新系統
由於 Hadoop 需要在 Java 環境下執行,所以我們需要安裝 Java JDK。Java JDK 大致分為 OpenJDK 和 OracleJDK 兩種。因為 OpenJDK 設定上較為容易,因此本次使用 OpenJDK 1.8。其後需要用 wget 工具在 Hadoop 官網下載 Hadoop 安裝包和測試用文檔,在如圖 8 所示下達【sudo yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel wget】命令一拼安裝 OpenJDK 1.8 的基本和開發者套件及 wget 工具。下載和安裝完成後,會出現 Complete! 的字樣。

圖 8 安裝 Hadoop 相關套件
然後設置 Java 的系統環境變數,供 Hadoop 識別 Java JDK 的位置。設置完成後,可以使用 $JAVA_HOME/bin/java –version 同 java –version 驗證設定,兩句指令均應獲得一致的 Java 版本資訊。在如圖 9 所示,這裡同樣使用 sed 命令下達【sudo sed -I ‘$ a export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk’~/.bashrc】命令把 Java 環境變數直接加入到 ~/.bashrc,大家記得每次修改完 ~/.bashrc 都必須用下達【source ~/.bashrc】命令使其生效,最後下達【$JAVA_HOME/bin/java -version】或【java -version】命令檢查是否成功識別 Java JDK 的位置。
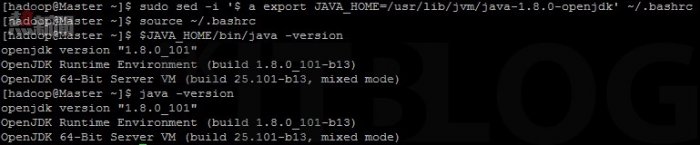
圖 9 設置 Java 環境變數
在如圖 10 所示,在 /etc/hosts 文件的最後方加入全部虛擬機的 IP 地址和對應的主機名稱。修改完成後,我們可以如圖 11 所示下達【ping -c 4 Slave1】命令測試能否解釋電腦名稱。
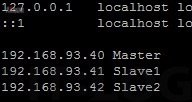
圖 10 設置 /etc/hosts 文件
圖 11 使用 ping 指令測試
待續……
深入 Hadoop 大數據分析:請先由叢集中開始吧!
深入 Hadoop 大數據分析:初探網絡環境與設定
深入 Hadoop 安裝與設定:1.X 跟 2.X 版本最大分別是…?
深入 Hadoop 安裝與設定:1.X 跟 2.X 版本最大分別是…?
https://www.facebook.com/hkitblog










