





該來的還是來了。前天凌晨中國版 Prisma 發布,它的名字叫 「深黑」。
不管黑不黑,讀完本文你將看到:Prisma 前身德國初創企業 Deep Art 的獨家專訪;俄羅斯火爆全球的應用 Prisma 為何被德國人批評;圖像領域應用的玩法大盤點。
撰稿:季星 丁卡 加辰 房宮一柳
編輯:袁帥
顧問:丁曉誠 邢一男
製圖:房宮一柳
2016 年 8 月 16 日凌晨 00:01,一款名為 「深黑」 的APP 在 Android 平台上線公測版。簡介描述裡「基於人工智能」、「不同於傳統濾鏡」這些用詞,加上看作品畫風,讓人聯想起 2016 年大火、僅次於 Pokeman Go 的 APP—Prisma。

▲深黑的作品展示。圖片來源:http://www.oandf.cn/deepblack/index.html
Prisma 體現了當今人工智能時代,人們想要用電腦代替傳世畫家的野心。印象派、野獸派、浮世繪、波普、解構主義,曾經藝術風格都是畫家腦中不可捉摸的概念。而到了人工智能時代,所有藝術風格都被證實是可以進行 「量化」 的,通過機器學習,可以源源不斷地產生新作品。
在量化(數學)與風格(藝術)之間,吊詭的是時間。最勤奮的油畫畫家達芬奇,畫一幅普通作品也需要花費一周左右;而到了人工智能時代,這個時間是:不到 20 秒。
趁着中國版 Prisma 的發布,我們今天回顧一下深度學習的圖像應用。
把電腦 「調教」 成梵高
似乎歐洲國家對藝術這件事比其他地區更有群眾基礎。早在 2016 年 Prisma 大火的一年之前,就有三個德國研究員想把電腦調教成梵高。
這三個研究員名字分別叫做萊昂 · 蓋提斯(Leon Gatys),亞歷山大 · 埃克(Alexander Ecker)和馬蒂亞斯 · 貝特格(Matthias Bethge),來自德國圖賓根大學(University of Tübingen)的 Bethge 實驗室。他們研發了一種算法,模擬人類視覺的處理方式。具體是通過訓練多層卷積神經網絡(CNN),讓電腦識別,並學會梵高的 「風格」、然後將任何一張普通的照片變成梵高的《星空》。
Deep Art 首頁貼出得到一張 「梵高風格」 圖片的步驟。第一步,吸收用戶拍攝的照片。第二步,讓電腦學會星空圖的風格。第三步,電腦輸出自己做的「新畫」。
在人類的視覺系統中,從眼睛看到一件實體,到在腦中形成圖像的概念,中間經歷了無數層神經元的傳遞。底層的神經元獲取到的信息是具體的,越到高層越抽象。
這三個德國人發現,如果用電腦模擬這個網絡,將每一層的結構分析出來,能看到:在採樣過程中,底層網絡對於圖像的細節表達得特別清楚,越到高層像素保留得越少,輪廓信息越多。
所謂深度學習(Deep Learning)中的 「深度(Deep)」 即意為層數。神經網絡的每一層都會對圖片特徵進行提取,而 「藝術風格」 則是各層提取結果的疊加。
這三個德國人把他們的上述發現寫成了兩篇論文:《藝術風格的神經算法(A Neural Algorithm of Artistic Style)》,和《利用神經卷積網絡進行紋理合成(Texture Synthesis Using Convolutional Neural Networks)》,在學術圈引起極大的討論。
「起初,我們只是想創造一個關於神經科學的新鮮事物。而藝術人工神經網絡的狀態與人類的視覺系統有頗多相似之處。所以後來我們覺得,可以對圖片做更有趣的處理。」 萊昂 · 蓋提斯對深藍 Deeper Blue 說。
論文發表後不久,他們便建立了一家名為 Deep Art 的初創公司,着手實現他們在論文裡提出的想法。
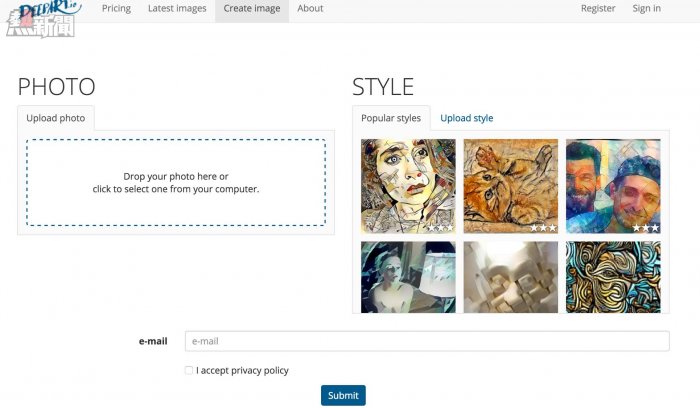
▲Deep Art 網站,圖像製作界面。Deep Art 提供多種藝術風格選項,圖像製作完成後需發至用戶郵箱。圖片來源: https://deepart.io/hire/
用戶在 Deep Art 網頁上上傳自己的照片,然後通過 Deep Art 提供的 「機械人梵高」 進行新畫創作。整個過程需要等待幾個小時讓電腦進行數據運算和處理。用戶可以選擇清晰程度不等的作品。用戶可以花上 19 歐買一張適合明信片用的作品,或者多掏 100 歐,買一張大尺寸油畫級別的。
萊昂 · 蓋提斯們做的事情並不是美圖秀秀的濾鏡。在 Deep Art 出來之前,已經有很多致敬莫奈與梵高的濾鏡類應用,但核心原理和 Deep Art 完全不同,比如 2010 年上架的 Mobile Monet, Van Gogh Camera 。

▲Camera Monet 與 Van Gogh Camera的界面展示。這兩款濾鏡軟件,都能講用戶照片渲染成某種藝術效果。但核心原理和Deep Art使用的卷積神經網絡完全不同。(深藍製圖)。
如果我們將同一張圖片放入 Van Gogh Camera 中,Van Gogh Camera 會按照程序員事先內置的 「公式」,計算圖中每一個像素點,最後輸出一張梵高風格的照片。但只要我們想將圖片風格從梵高換到畢加索,程序員就必須重新寫一套代碼,更改計算 「公式」。
而在 Deep Art 中,編寫 「公式」 的程序員是卷積神經網絡(CNN),只需輸入梵高的《星空》,卷積神經網絡便能自動提取這幅畫作的風格特徵,並量化成具體公式。也就是說,藝術史上所有的作品都能作為濾鏡來源。
「卷積神經網絡可以被看做是一個機器藝術家。」 萊昂 · 蓋提斯說。
從德國到俄羅斯
2016 年年初,俄羅斯電腦工程師阿列克謝 · 莫伊謝延科夫(Alexei Moiseyenkov)讀到了這三個德國人的論文。他敏銳地嗅到,德國人做的遠遠不夠,這項技術在消費級市場仍是一片空白。
隨後他組建了一個四人團隊,研發了 Prisma,力求做到:免費,更快,更簡單。「 兩個月研究數學模型,一個半月開發。」 莫伊謝延科夫說。
「 Prisma 第一次將這項技術成功商業化。他們充分考慮了智能手機覆蓋率的飛速增長,並且細緻研究了用戶行為。Prisma 接入的是以億數量級的市場。」 《莫斯科時報》這樣報道他們:「 誰抓住了用戶需求,誰就能成為億萬富翁。」
Prisma 的橫空出世,算是俄羅斯互聯網圈子少有的高光時刻。2016年6月中旬,這款應用剛在 iOS 上發布,15 天內下載量 750 萬,火遍四十個國家。
巨大的成功甚至讓開發團隊措手不及,不得不以每天擴大一倍的速度提升服務器處理能力。
「看起來,整個俄羅斯都被我們征服了。」 莫伊謝延科夫隨後在 Facebbok 上寫下了這句話。8 月 2 日,Prisma 全球範圍內已獲得超過 5000 萬用戶。

▲坐擁 2300 萬粉絲的俄國總統梅德韋傑夫也成為 Prisma 的用戶。他在 Instgram 上曬出一張 Prisma 作品,迅速獲得 8.7 萬個贊。
Prisma 比 Deep Art 先進的地方在於,它大大縮短了圖像處理的時間。在用戶還沒有達到十幾億數量級的時候,每張照片在 Prisma 系統內的處理時間只有 20 秒。其次,Prisma 是一款免費手機應用,相比網頁版的 Deep Art, 無疑具有更多的用戶基數。
20秒,全球的某個角落,一個用戶上傳照片,他的照片被傳送到位於莫斯科的服務器上,Prisma利用人工智能和神經網絡進行處理,然後經 「風格化」 後的圖片再返回用戶手機。
這個速度在業內是頂級的。為什麼這麼快?
「一定是下了血本,」一位來自國內著名人臉識別技術公司的工程師告訴深藍 Deeper Blue,「在我當時搭建的框架之下,用普通筆記本的計算能力,做一張這樣的圖有可能需要幾個小時。」
德國人萊昂 · 蓋提斯則對深藍 DeeperBlue 猜測道:「我認為他們訓練了一個前饋神經網絡來製造圖片。」
「Prisma 沒有完全依賴機器學習,而是對一些關鍵的內容加以控制。」一位業內人士則對深藍 Deeper Blue 說,「例如,在海量的用戶上傳內容中,一定有相當一部分比例是人像,而相對於原始算法,Prisma 對面部細節的處理似乎更勝一籌,也許他們專門加入了對面部的識別和控制。」
據莫伊謝延科夫自己介紹,Prisma 一共用了三組神經網絡,它們分工明確:兩組神經網絡負責的風格提取和照片製作,還有一組神經網絡作為後台,為整個計算過程加速。
相比之下,Deep Art 更像是精工細作的手藝人。萊昂 · 蓋提斯認為自家的原始算法雖然慢一些,但在細節表現力上更勝一籌—— 「是真正的藝術品。」 Deepart.io 提供的收費高分辨率大圖,堪比一副掛在博物館牆上的畫。
▲Deep Art 主頁上,關於作品定價的界面展示。圖片來源:https://deepart.io/pricing/
「他們的風格化工作比最初的工作要弱了些,我認為他們是做了一些較低級別的圖片處理,以掩蓋風格化的不足,例如,加強了邊緣的表現。」 萊昂 · 蓋提斯對深藍 Deeper Blue 說,他認為 Prisma 犧牲了藝術質量而求速度。
群雄逐鹿
大部分人之前推測 Prisma 會推出更多濾鏡來變現,但在 Prisma 主創拜訪過 Facebook 之後,爆出他們的下一步的計劃是做視頻。2016 年 7 月20 日,Prisma 創始人莫伊謝延科夫在 Facebook 官方賬號上上傳了一段 29 秒的音樂視頻。這段視頻的每一幀,都經過藝術風格渲染。

▲一段 Prisma 藝術效果視頻。Prisma 已經在官方 Facebook 上發布了多個音樂視頻。
然而,並不只有 Prisma 一家在轉視頻這個方向。
僅僅隔了 9 天,Prisma 的天使投資方、俄羅斯互聯網巨頭 Mail.Ru 公司副總裁安娜 · 阿塔莫諾娃(Anna Artamonova)在 Facebook 上宣布了 Prisma 直接競品 Artisto 的發布。這是一款結合神經網絡和人工智能技術的視頻處理軟件,可以為視頻添加動態的藝術特效。雖然視頻長度不能超過 10 秒,但名畫風格的圖像 「動起來」 確實賞心悅目。阿塔莫諾娃稱這個視頻軟件只花了 8 天時間研發。
▲副總裁 阿塔莫諾娃接連在 Facebook 上發布 Artisto 製作的視頻。 圖片來源:https://www.facebook.com/artamonova/videos
在 Prisma 安卓版上線的第二天,俄羅斯最大社交網站 VKontakte 也推出了一款和 Prisma 類似的產品:Vinci,兩者的功能和外觀都非常相似。Vinci 不僅將圖片加工時間縮短到了 2 秒鐘,還快速開放了 iOS 與 安卓市場,並且覆蓋到 Prisma 未能涉足的 Windows Phone 領域,成為 Windows Phone上第一個運用神經網絡的軟件。值得一提的是,社交網站 VKontakte 也是 Mail.Ru 的旗下產品。
截至到 2016 年 8 月 2 日,在俄羅斯 APP Store 免費榜上,Artisto 高居榜首,Vinci 位居第二,而 Prisma 則落到了第五的位置。
▲圖片製作軟件 Vinci 的界面展示。圖片來源:http://mspoweruser.com/vinci-great-alternative-prisma-now-available-windows-mobile-devices/
不僅僅是俄國人在想視頻這件事,Deep Art 那三個德國人也瞄準了視頻市場。前不久,Deep Art 官方網站放出了一段 demo,開始製作付費短視頻。一段 720p的視頻(最長五分鐘)售價 249 歐元。
Deep Art 的產品高價位和慢速度,定位的是中高級市場。而在大眾消費端,免費產品 Prisma,Vinci,Artisto 不論誰贏,都是俄羅斯互聯網巨頭公司 Mail.Ru 的勝利。與其說幾款產品是在技術上較量,不如說這是互聯網資本大鱷的強勢布局。
然而,事實上深度學習在視頻上還處於起步階段,主要面臨如下三個挑戰:
第一,視頻的數據處理量比圖片更大,對計算能力的要求指數級增加;
第二,如何保持幀圖像在時間軸上的信息一致性,而不是單獨處理每一幀圖像,也是難題;
第三,視頻中的物體時刻在運動,如何追蹤其在空間中的動態變化,研究員們還沒找到好的方法。
除了我們盤點過的這些 「濾鏡類應用」,深度學習在圖像處理上應用還有很多。總的說來,深度學習圖像應用按照過程可以分為兩部分:輸入與輸出。
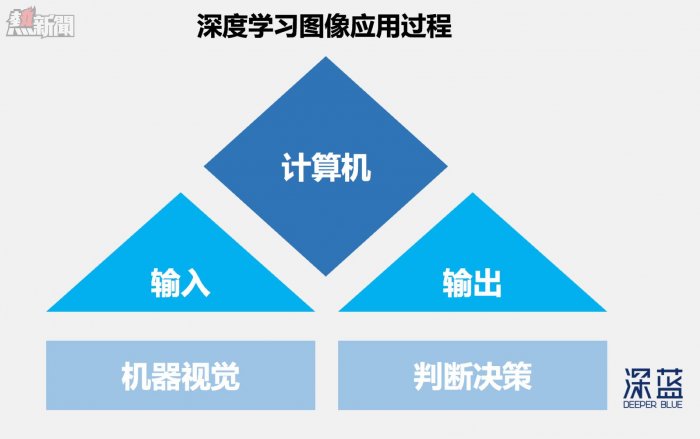
輸入可以視作是 「機器視覺」,即機器內部建立起對圖像的理解與認知——比如去判斷圖片中人像是不是本人,對圖中物品進行分類等;
輸出是進一步做出判斷、決策,並觸發行動,比如自動駕駛中通過分析攝像頭採集到的道路信息,對控制系統下達加速、停車等指令。
在圖像識別的高準確度的基礎上,深度學習能夠完成更為複雜的任務。舉個例子,如果說百度圖片搜索、微博自動檢測圖片中的敏感詞屬於電腦理性認知層面應用的代表,那麼像 Prisma 這樣的應用就是在深度學習的幫助下,讓電腦不僅可以理性識別,還能感性認知圖片,理解圖像的風格與內容關係。
這才是人工智能的意義所在。電腦感知能力的發展決定了機器世界能否真正建立自洽、完整的知識體系,最終實現對人類能力的替代、延伸和增強。
按領域內容,深度學習在圖像中的應用分為:圖像識別、分類、檢測、搜索、特徵提取和視頻處理這幾大類別。其中,人臉識別是突破最快的深度學習圖像應用。早在 2014 年便有多個初創科技團隊達到了逼近或者超越肉眼的識別率,如下圖展示:
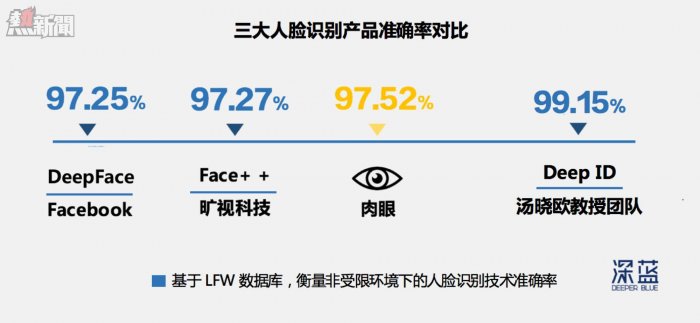
▲各公司利用自己的公開樣本集測試,提交測試結果。結果顯示,湯曉鷗教授團隊研發的人臉識別產品 Deep ID 已經超越肉眼的識別率。其中,小橫線上面是技術產品名,下面是團隊名稱。(深藍製圖)
這幾家公司中,Facebook 已經將 Deepface 的成果整合到自家產品中了。如今,用戶上傳照片到 Facebook 賬號,系統就能自動標注圖中的每一個人。而曠視科技和以湯曉鷗教授為技術核心的 「商湯科技」,則主要為金融、安防等部門提供成熟的身份認證產品,客戶包括支付寶、招商銀行、反恐部隊等。
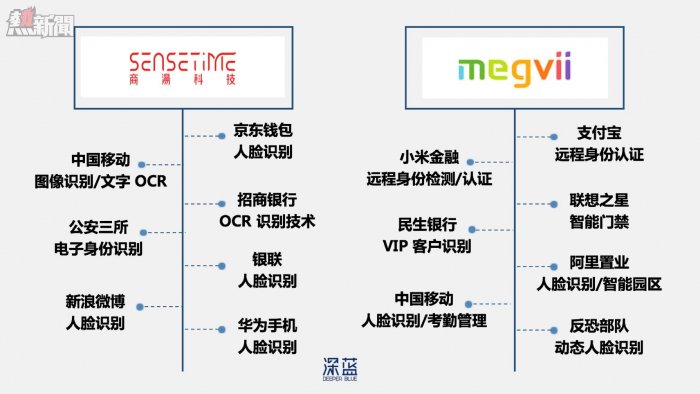
▲商湯科技與曠視科技主要客戶對比圖(深藍製圖)
Facebook 可能是這三家巨頭中對深度學習圖像應用最具有野心的大公司。據內部可靠消息,Facebook 或將在下周末(2016年8月底)將他們最新的研究成果代碼開源。如果用一句最簡單的話來形容 Facebook的新突破,叫做 「採用無監督學習讓電腦無中生有,自己生成圖片」。

▲三大互聯網公司在深度學習上的布局一覽。(深藍製圖)
在以往,人們讓電腦去做圖像生成採用的是監督式學習,即需要利用大量帶標籤的數據去訓練人工神經網絡,後者才能逐漸學會識別東西。比方說,給電腦看 1000 張貓的圖片,看多了之後神經網絡會逐步對貓建立模型並識別其他貓的圖像。
但在今天,Facebook 採用的是無監督學習,讓電腦自主生成一些含有飛機、汽車、小鳥等東西在內的場景圖像樣本,並令觀眾信以為真。
Google 的 Deep Dream 是一個會畫畫的電腦。它自動識別圖像,篩選出某些部分,進行誇張,以創造出一種迷幻效果。半年前,Deep Dream 於灣區舉辦了成功的畫展。Deep Dream 模仿 500 年前文藝復興時期的德國畫家漢斯·荷爾拜(Hans Holbein)的筆觸與繪畫技巧,畫出了一系列硅谷名人。每張畫作足以讓人們掏出幾千美金來收藏。
然而,Deep Dream 的算法有時候會給人驚嚇。如果它發現你的臉部線條有點像一隻狗,於是它會把那一塊區域畫成一個完整的狗。「這就像吃了 LSD,電腦會出現幻覺。於是到處都是狗!」 一位來自 Google AI Lab 的員工說。

▲Google Day Dream 的畫作。圖畫中不少區域被電腦處理成狗頭、漩渦。
無論如何,電腦正在向我們展示它們自己的夢想。
參考文獻:
i, Gatys, Leon, Alexander S. Ecker, and Matthias Bethge. "Texture synthesis using convolutional neural networks." Advances in Neural Information Processing Systems. 2015.
ii, Gatys, Leon, Alexander S. Ecker, and Matthias Bethge. "A neural algorithm of artistic style." arXiv preprint arXiv:1508.06576 (2015).
ii, 王曉剛. "深度學習在圖像識別中的研究進展與展望". 2015.
iii, Venture Scanner. Artificial Intelligence Market Overview. 2016.
iv, He, Kaiming, et al. "Deep residual learning for image recognition." arXiv preprint arXiv:1512.03385 (2015).
v, Denton, Emily L., Soumith Chintala, and Rob Fergus. "Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks." Advances in neural information processing systems. 2015.
vi, Sun, Yi, et al. "Deep learning face representation by joint identification-verification." Advances in Neural Information Processing Systems. 2014.
vii, Sun, Yi, Xiaogang Wang, and Xiaoou Tang. "Deep learning face representation from predicting 10,000 classes." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014.
viii, Sun, Yi, et al. "Deepid3: Face recognition with very deep neural networks." arXiv preprint arXiv:1502.00873 (2015).
歡迎轉載,如需授權,請聯繫微信號:jixingjoyce
還嫌 Prisma處理圖片太慢,你知道它有多努力嗎?











