





近年來,深度學習已有飛躍性的進展。以影像辨識、聲音辨識為始,廣泛運用在不同領域上。所謂的深度學習,是運用具備多層構造的類神經網路,讓電腦學習事先準備好的資料,進而提升辨識精準度。然而,若電腦過度學習資料,則會出現「過度訓練」的現象,也就是只有學習過的資料才有較高的辨識精準度,辨識從未學習過的資料時精準度就會下降。為了避免這種情況的發生,通常會使用「正規化」方式,來調整深度學習的過程。
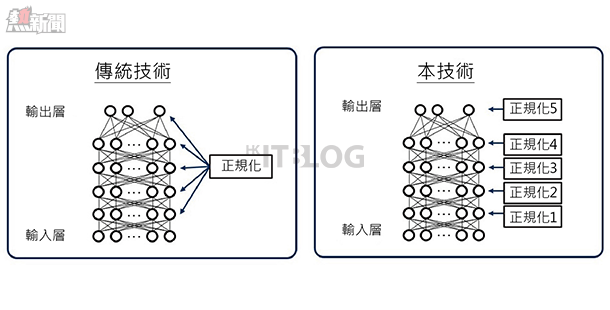
類神經網路的學習過程,會因應結構而產生複雜的變化,所以過去只能對整個類神經網路進行同樣的正規化方式。結果在類神經網路各層之中,有些出現過度訓練現象、有些則無法順利學習等問題,因而難以充分發揮原有的辨識效能。此外,由於逐一手動調整各層學習進度極為困難,市面上對自動化調整的需求呼聲也相當高。
近日我們收到來自 NEC 的通知,她們指出現正著手研發一種技術,該技術是依據類神經網路的結構,預測每一層的學習進度,並因應各層學習進度逐層自動設定正規化。透過這樣的技術,能夠優化整個類神經網路的學習情況,與傳統作法相比,更能降低 20% 的辨識錯誤率,辨識精準度有所改善。
運用有關技術,能在影像辨識及聲音辨識等運用深度學習技術的各個領域,能夠進一步提升辨識的精準度。例如,提升人臉辨識與行為解析等影像監控的辨識精準度,在基礎設施等處進行保養點檢時提升效率,更可望自動檢測出故障、事故或災害等情況。
新技術的優點
1. 依據類神經網路的結構,自動優化學習情況
依據類神經網路的結構,預測每一層的學習進度,並因應各層學習進度逐層自動設定正規化。透過這樣的技術,能夠優化整個類神經網路的學習情況,也解決了過去各層過度訓練、無法順利學習的問題。不僅如此,運用本技術進行辨識實驗,在辨識手寫數字的影像資料時,降低了約 20% 的辨識錯誤率,辨識精準度有所改善。
2.計算量與過往相同,也能輕鬆達到高精準度
在類神經網路進行深度學習之前,只須運行本技術一次,即使學習的計算量與過往相同,也能輕鬆達到高精準度。
專家研發深度學習自動優化技術:期望能更簡易提高辨識精準度!
https://www.facebook.com/hkitblog











