




前面我們已針對 Hadoop 叢集完成相關的配置,下一步會運行 Hadoop 內置程式 Wordcount,它可以計算文字檔內字詞出現的次數,但只限於英文。看似作用不大,但你試想想我們只要計算世界上最受喜歡的一萬本書,就會得出最常使用的字詞,我們只要學習這些生詞就可以看懂世上大部分的英文文章和書藉。
這次選用的書本是 The Hunger Game 四部曲。首先如圖 38 至 41 所示使用 wget 工具將四本書下載到 Master。
下載網址:
https://sites.google.com/site/the74thhungergamesbyced/download-the-hunger-games-trilogy-e-book-txt-file/%281%29%20The%20Hunger%20Games.txt
https://sites.google.com/site/the74thhungergamesbyced/download-the-hunger-games-trilogy-e-book-txt-file/%282%29%20Catching%20Fire.txt
https://sites.google.com/site/the74thhungergamesbyced/download-the-hunger-games-trilogy-e-book-txt-file/%283.1%29%20Mockingjay.txt
https://sites.google.com/site/the74thhungergamesbyced/download-the-hunger-games-trilogy-e-book-txt-file/%283.2%29%20Mockingjay.txt

圖 38_ 下載第一本書

圖 39_ 下載第二本書

圖 40_ 下載第三本書

圖 41_ 下載第四本書
在如圖 42 所示,下載完成後可以下達【ls -l ~/】命令看到剛才下載的四本書。並接著如圖 43 所示,由於書本的名稱有特殊字符,需為書本重新命名。

圖 42_ 查看四本書
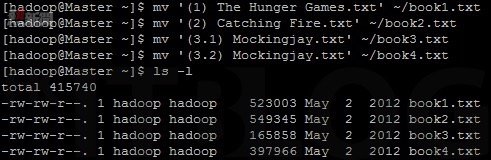
圖 43_ 重新命名書本
接着將書本移至 HDFS 目錄。管理 HDFS 的命令集有兩種,分別是【hadoop fs】和【hdfs dfs】,前者命令較類近於日常 Linux 的 Shell 命令,後者較類近 HDFS 原生操作方式。為了讓大家較容易明白 Hadoop 的運行方式,本次使用【hadoop fs】命令集。
如圖 44 所示,首先在 HDFS 目錄下達【hadoop fs -mkdir /wordcount】命令新建一個 wordcount 目錄,以提存放書本。然後如圖 45 所示下達例如【hadoop fs -copyFromLocal ~/book1.txt /wordcount】命令將書本複製到 wordcount 目錄下。繼續如圖 46 所示執行 Hadoop 內置程式 wordcount,只需下達【hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount /output】命令將結果輸出到 HDFS 的 output 文件夾內。

圖 44_ 建立 wordcount 目錄

圖 45_ 複製書本

圖 46_ 執行 wordcount 命令
在如圖 47 所示,使用者可以瀏覽【192.168.93.40:8088】看到 wordcount 程序的運行情況。並且如圖 48 所示 wordcount 運行完成後可以在 Master 看到 wordcount 程序扼要。在如圖 49 所示可以瀏覽【192.168.93.40:50070】於 Name 看到運算結果文件 — part-r-00000。
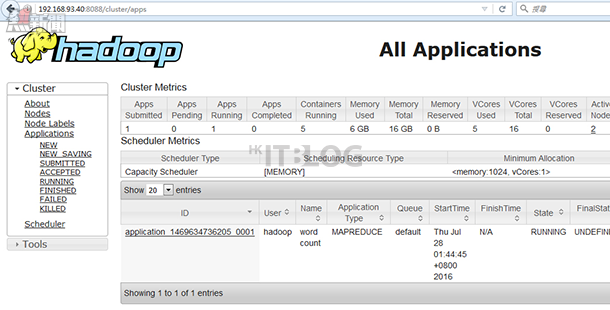
圖 47_ 檢查 wordcount 程序
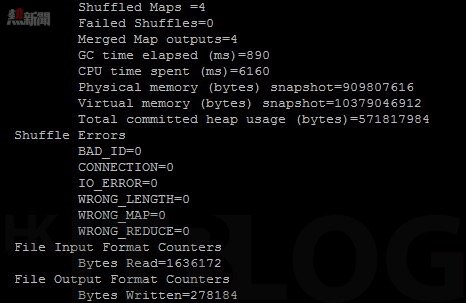
圖 48_ wordcount 程序扼要
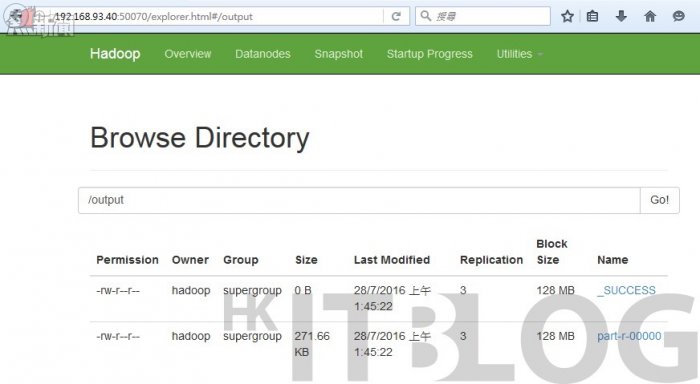
圖 49_ 運算結果
在如圖 50 所示由於 Centos 7 Minimal 並沒有 GUI 介面,所以要下達【hadoop fs -copyToLocal /output/part-r-00000 ~/wordcount_rescult.txt】命令將運算結果複製至本地 /home/hadoop/wordcount_result.txt。並接著如圖 51 所示下達【cat ~/wordcount_result.txt】命令複製如圖 52 所示的運算結果。

圖 50_ 複製運算結果
圖 51_ 使用 cat 命令
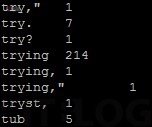
圖 52_ cat 命令顯示運算結果
額外提示
如果日後想增加 Slave 的話,要在先前的 Master和 Slave 下達【sudo rm -r /usr/local/hadoop/tmp\, sudo rm -r /usr/local/hadoop/logs/*】命令z,清除先前的 Hadoop 的暫存和日誌檔。
總結
通過這次教學相信大家已經對架設大數據分析伺服器架構有所了解。整個測試過程中,遇到最大的因難是設置 ~/.bashrc,這個檔案可以說是整個系統的中樞神經,其定義 Hadoop 各核心文件和插件的位置,如設置不當就會出現大量不知明的警告和錯誤信息。
Hadoop 只是大數據分析的其中一部分,您可以配合 HBase, Hive, Zookeeper, Spark 等一整套由 Apache 基金會研發的 Hadoop 周邊套件完成更複雜的分析任務,當中 Spark 更可允許用家使用 Python, Scale 等程式語言編寫大數據分析程式。
瀏覽相關文章
深入 Hadoop 大數據分析:請先由叢集中開始吧!
深入 Hadoop 大數據分析:初探網絡環境與設定
深入 Hadoop 安裝與設定:1.X 跟 2.X 版本最大分別是…?
深入 Hadoop 安裝與設定:SSH 私有鑰匙設定與安裝
深入 Hadoop 安裝與設定:SSH 私有鑰匙設定與安裝(1)
Wordcount 測試實作:教你以 Hadoop 進行簡單文字分析!
Wordcount 測試實作:教你以 Hadoop 進行簡單文字分析!
https://www.facebook.com/hkitblog










