





本文分三段刊載於作者微信公眾號「字典序列」及頭條號「詞典序列」。
1、傳統媒體:為什麼人們曾經像超市賣商品一樣販賣信息?
Target很早就開始通過線下超市的結算系統,記錄會員的消費情況,比如你在某一天走進一家Target,買了一聽可樂,當你掃碼結賬的時候,這些消費數據都會被記錄進你的會員數據庫中。從中,Target可以挖掘出一些營銷機會。
於是2003年的時候就出了這麼一件事。一天,有一個中年男子走進明尼蘇達州的一家Target超市,要求見店長。在店長的辦公室里,這個男人拿出一疊優惠券,告訴店長,這些都是Target通過電子郵件發給他上高中的女兒的。這些優惠券幾乎全部是關於嬰兒用品的:嬰兒床、嬰兒玩具、嬰兒服裝、護理用品等。在這位男子看來,Target給一位高中生投遞這樣的促銷信息,是極不尊重的。
店長也不得不同意他的看法,於是他請這位男子先回家,並承諾會給他一個答覆。在做了幾天的調查之後,他確信是Target的電子營銷部門犯下了錯誤,並打電話給這位男子向他道歉。

他沒想到的是,這位男子卻先向他道歉了,他說回到家后他向家人了解了情況,才知道自己的女兒確實已經懷孕了,預產期就在3個月以後。
為什麼一家超市能比這個少女的父親更早知道她已經懷孕了呢?
答案就在Target的數據庫里。根據數據挖掘的結果,Target發現,女性經常在預產期前3-5月的時間點開始,消費這四種商品:無味的潤膚露和肥皂、大包裝的棉球、包括鈣鎂鋅在內的孕婦營養品。所以,如果系統發現某位女性消費者開始在Target購買這幾件特定的商品,就會向她發送關於嬰兒用品的促銷信息。

儘管讓這位女性的父親產生了些許不快,但是毫無疑問,這樣精準的信息推薦,對於當事人本人是非常有用的。如果某個家庭將在3個月內迎來一位新的成員,而家中沒有任何她可能用到的東西,你無疑會感到焦慮和無助。這時,一封恰到好處的郵件,能給你帶來很大的幫助。
不幸的是,大多數超市並沒有那麼發達的數據庫和數據挖掘技術,因此,多年以來我們所熟悉的超市宣傳物料看上去是這個樣子的:

收到這樣一份把上百條促銷信息塞在一張紙上的宣傳品,你的第一反應是什麼?我的第一反應是扔掉。你幾乎可以肯定其中有一兩件商品是你需要的,但是你不知道它們在哪裡。在這樣一份琳琅滿目的單頁里找出這些有用的信息,然後省上個五毛一塊錢,絕對是一件得不償失的事。
難道超市的營銷團隊不知道這樣的信息對消費者來說沒有用嗎?他們當然知道。但是,如果想要實現Target那樣高精準度的信息推薦方式,至少要解決兩個技術問題:
能夠知道每個受眾所需要信息是什麼;能夠為每個受眾定製他所需要的信息。
然而在一個沒有消費者全量數據的商業機構里,第一點是無解的。在傳統企業里,人們也會做消費者調查,但全都是小樣本量的抽樣調查。以超市這個行業為例,訪問員可能會隨機地在超市附近尋找消費者,對他們進行不具名的問卷調查,然後得到一些類似這樣的結論:
50%的人每周到訪超市一次;
35%的人每次到訪超市的消費額度在100元以內;
80%的人會購買快速消費品;
0.5%的消費者是孕婦。
根據這樣的信息,經營者能夠對「該對消費者說什麼」這件事有一個簡單的判斷(例如,宣傳單上應該有80%的篇幅是關於快速消費品的),但是想要做到精準的信息推薦和信息生產,是絕無可能的。我們知道200個人里有一個是孕婦,但是不知道她是誰,這樣的信息又有什麼用呢?難道隨機地在200份宣傳單中夾上一份關於嬰兒用品的宣傳品嗎?
因此,對於超市來說,最為經濟的信息傳播模式就是:把消費者「最有可能」感興趣的信息堆在一起,一股腦地塞給用戶,然後讓用戶自己完成信息的過濾和篩選,選擇性地接受其中與自己需求匹配的信息。
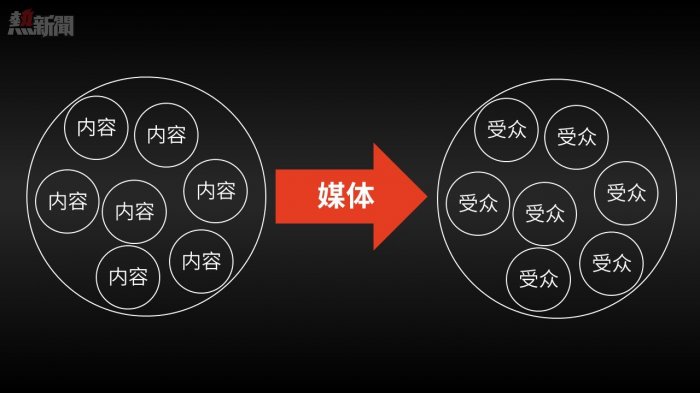
而這種傳播模式,其實也是過去數百年間媒體行業的主流模式。
這是前幾天某都市報的兩個版面:

其實,這就是超市宣傳單的一種翻版:把受眾最有可能感興趣的信息打包放在一起批發給用戶,讓用戶自己完成信息的篩選和匹配工作。
我在一家知名平面媒體工作過。時不時地,我們也會嘗試對媒體提供的信息與用戶的需求之間做重新的適配工作,這個工作在媒體一般被稱為「改版」。我們會通過以下方法獲取「改版」所需要的信息:
讀者抽查;
對過往媒體內容的讀者的歷史反饋;
同行評價;
資深編輯記者的品味、經驗。
「改版」主要會包括以下一些改變:
讀者最有可能感興趣的內容,給予靠前的版面順序和更大的版面規格;
讀者有較小可能感興趣的內容,給予靠後的版面順序和比較小的版面規格;
有極少部分讀者會感興趣的內容,可能會從版面上放棄。
不過,無論如何改造,一切還是以「打包」的方式進行的。因為媒體行業面臨的問題和超市行業並無本質不同:我們無法精準而完整地知道每個用戶想要什麼。
當然,在傳統媒體時代,我們還面對着另一個問題:信息生產的成本問題。即使我們能夠知道每個用戶的需求,要在物理世界中為他們定製信息(印刷)以及分發信息(線下發行),會產生任何一個媒體機構都無力承擔的巨大的成本。
不過,這一點在互聯網興起之後很快便不是一個問題。互聯網讓信息的發布和留存成為了一件極低成本的事情。但是,在很長時間內,前一個問題仍然沒有好的解決方案。所以,我們在很長時間里,看到的網絡媒體是這樣的:
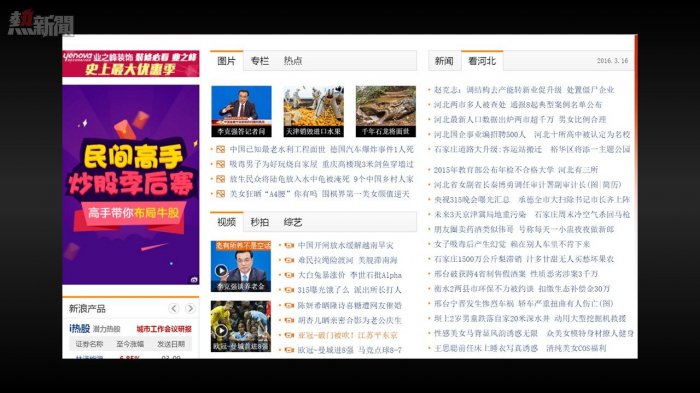
以「門戶」模式為代表的媒體形態,存放和發布信息已經幾乎不再受到物理成本的約束。因此,一個顯著的改變就是,媒體所容納的信息越來越多。上面這個截圖裡出現的信息,可能已經達到以前一份報紙的信息容量的上限。而這僅僅是一個網站的局部。
選擇變多了,篩選成本也更高了,根本上說,這種模式和傳統媒體並沒有什麼區別。所以,在媒體網絡化的早期,人們經常談論的一個擔憂就是:「信息爆炸」。
再回顧一下傳統媒體時代(包括門戶網站等早期網絡媒體形態),信息的分發模式:
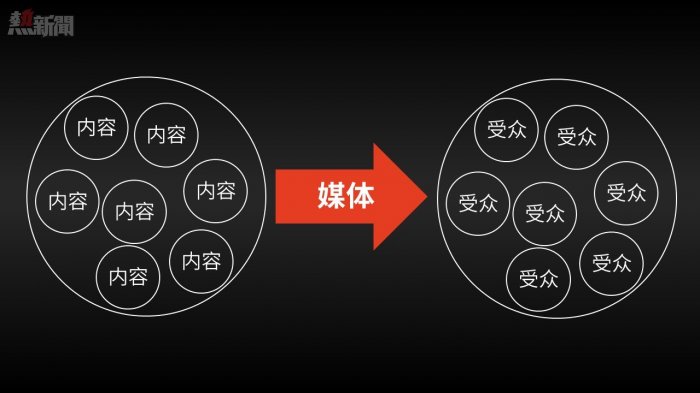
為什麼無論是網站,還是報紙,都會用和超市推銷商品一樣的方式向受眾販賣信息呢?因為他們思考的方式和超市並無不同。
不是因為他們不願意,而是因為他們做不到。
2、社交媒體:一場各盡所能、各取所需的社會實驗
如果今天晚上你想在家裡招待客人,需要購買一瓶葡萄酒,你會選擇去以下哪個商店採購?
精品便利店,有3種進口自波爾多的紅酒,以及2種進口自澳大利亞的新世界紅酒;
大型進口酒類超市,有300多種來自世界多個不同產區、品種各異的紅酒,其中也包括上面說到的5種酒。
如果不考慮地理位置、採購預算等具體因素,你會選擇去哪裡,可能完全決定於你是什麼樣的人。如果你是一個對葡萄酒一無所知或者剛剛入門的消費者,你會選擇A;如果你是一個專業的品酒者,你很可能會選擇B。
就最終的消費選擇而言,一個人不可能從A商店里挑出比B商店更適合自己的酒。但是為什麼大多數人都會傾向於A呢?因為篩選信息是有成本的。品酒專家會選擇B商店,不僅是因為他們對酒的品質更加挑剔,也是因為他們能迅速地篩選信息,做出最優的消費決策。
人們常常說自己面臨著「選擇困難症」,他們真正的意思是:選擇的代價太高了。著名的科技作者Clay Shirky(《眾包時代》、《未來是濕的》、《認知盈餘》等書作者)曾針對「信息爆炸」這一現象做出一個極有洞察力的論斷:「這不是信息過載,而是過濾失敗。」
進入到互聯網時代以後,發布和存放信息的物理成本持續降低,刺激着信息生產的不斷增長。於是降低信息的「篩選成本」就成了媒體行業的重要命題。
現在再來設想一下,如果你只有B商店一個選項,而你非得從中挑出一件符合你需求的酒,你該怎麼辦?如果是我,我會叫上一位懂酒的朋友和我一起挑選。這就是通過「社交關係」向用戶推薦信息的模式:「社交媒體」的基本模式。
Twitter大概算是最早的一個成熟的社交平台產品,隨後興起的facebook、Instagram、微博、微信朋友圈等等,已經徹底改變了人類獲取信息的方法和習慣。
社交媒體分發信息的模式有兩個最核心的優勢:
每個用戶都參與信息的分發,如果你有1億個用戶,你就有1億個編輯去分析、篩選和分發信息;
用戶分發的信息總是先達到和自己有直接社交關係的其他用戶,「關注」關係的雙方要麼是物理世界中的朋友、同事,要麼是在網絡世界中的興趣相投者。因此,一方對信息的篩選,有很大的可能符合另一方對信息的需求。
總而言之,社交媒體不僅顯著擴大了人類處理信息的勞動力總量,而且提升了單個信息節點接受信息時的匹配質量。對於「過濾失敗」這一挑戰來說,可謂是一個屬於人類的里程碑式的勝利。
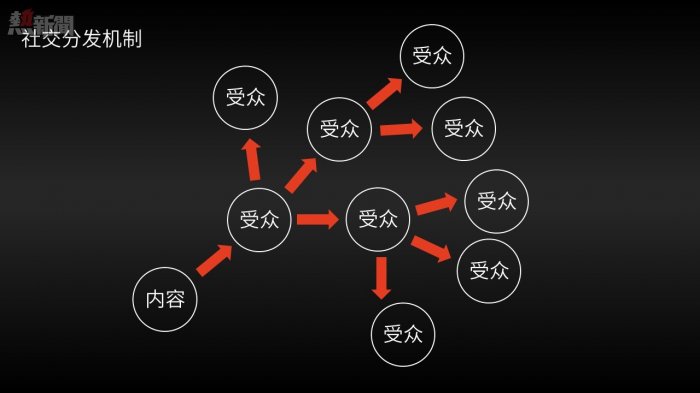
那麼,參與社交媒體的用戶們得到了什麼呢?
通過關注另一位用戶,你得到了更多的符合自己需求的信息(各取所需);
通過轉發和分享,你可以施展自己的所長,並維繫自己的社交關係(各盡所能)。
各取所需、各盡所能,一個看上去很完美的解決方案,但它真的完美嗎?很遺憾,就像人類歷史上其他一些試圖根本性解決人類問題的社會化實驗一樣,這個「完美」的信息分發模式也存在着缺陷。

首先是效率問題
在傳統媒體,某個版面編輯經常對接的內容生產者(記者、撰稿人等)一般在25-50個之間。然而,如今如果統計某個人在各種社交平台上的社交關係,那麼有極大的可能性,你會得到一個遠遠超過30的數字。
直觀地說,就是每個人的「微博」和「朋友圈」都「看不過來」了,而這種「看不過來」又會直接影響我們向其他人分發信息的質量和精確性,形成了惡性循環。
如果你同時找30個葡萄酒專家給你意見,而他們每個人又要同時給30個客戶提供意見的話,那麼信息過濾又會重新成為一個問題。

第二個問題是:公平問題
Clay Shirky另一個非常著名的論斷是他談論「眾包」時提出的:「互聯網是愛的大本營。」可惜的是,互聯網同時也是「自利」的大本營。
社交分發模式允許人們以「眾包」的方式篩選和分發信息,但是這並不等於每一個社交節點的分發權力是平等的。如果一個人(KOL、網紅、公共知識分子……)掌握了比其他人更大的信息流量分配權,那麼他就會受到激勵去生產或者發布那些對「他自己」而非「他的關注者」有價值的信息,例如廣告、軟文、片面的觀點等等能讓發布者本人從中獲利的信息。
想像一下,當你走進葡萄酒商店的時候,一位受聘于廠家或者商家的「品酒專家」向你推薦了幾款葡萄酒——這些酒更可能是符合你的需求,還是符合廠家、商家的利益?
以上兩個缺陷,會導致「社交分發」這個貌似完美的社會實驗發生「退化」:越來越多的人越來越不負責任地生產、過濾和分發信息,從而人為地、重新製造了「過濾失敗」。這種「退化」最典型的例子就是「微博」:「大V」們輕輕點擊轉發按鈕就可以賺取巨大利益,而絕大多數用戶只能被迫接受他們分發的低質信息。
那麼微信呢?儘管抱怨「朋友圈」水化、「公眾號」看不過來的聲音已經不少見,但目前看來,它的「退化」並不像微博那麼迅速和徹底。因為微信一直在通過各種手段抑制這種「退化」:
個人用戶的關注列表被限制在5000個以內;
沒有節點數量限制的「訂閱號」,被摺疊進「訂閱號」抽屜中,並且每天只能推送1次信息;
沒有節點數量限制也沒有被摺疊的「服務號」,被限製為每月只能發送4次信息。
然而,這不是「解決方案」,而是「權宜之計」。它以犧牲信息總數量和豐富性為代價,緩解了「過濾失敗」現象的出現速度和嚴重程度。
有沒有一種更加完美的解決方案呢?有沒有一家應有盡有的葡萄酒商店,不會被品酒專家和混在其中的酒托們擠得水泄不通,而又能讓任何一個想要買酒的人高效精準地找到適合自己需要的那瓶酒呢?
3、智能媒體:從搜索引擎到推薦引擎
如何在不詢問本人(以及她的家人、朋友)的前提下,知道一位女子已經懷孕了?Target超市通過消費者數據庫解答了這個問題。
根據消費者在超市的購物時記錄下的數據,他們發現:如果一個消費者在某個時間點轉變了消費習慣,開始購買:
無味潤膚露
無味肥皂
大包裝的棉球
包括鈣鎂鋅等微量元素的保健品
那麼,她有極大的可能在3-5個月后,開始持續採購嬰兒用品——換句話說,她是個孕婦。當Target在消費者數據庫中發現一位符合這些「特徵」的用戶時,他們就會向她發送一封包含嬰兒用品促銷信息的郵件,實現一次信息與受眾的精準匹配。
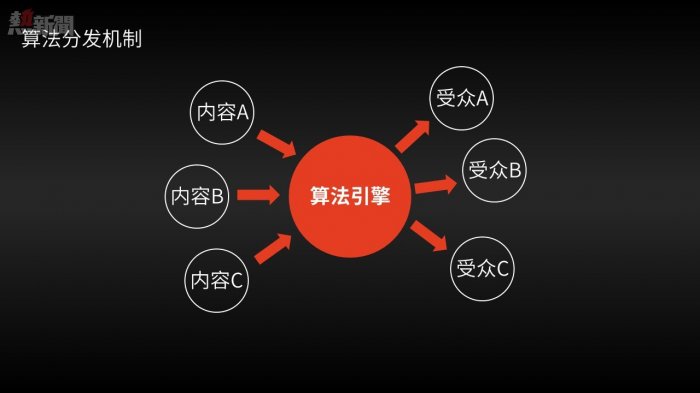
「智能媒體」模式的優勢在於,允許用戶與符合其需求的信息實現直接匹配,而不需要通過;
媒體精英的過濾和推薦(傳統媒體);
社交關係的過濾和推薦(社交媒體)。
社交媒體的出現,優化了「信息過濾」的兩個問題:
通過「眾包」,顯著擴大了社會處理信息過濾的勞動力總量;
基於線下關係或者相似需求的「關注」關係,使分發方提供的信息,更有可能符合接收方的需求。
然而——在理論上說——智能媒體可以在這兩件事上都做得比社交媒體更好。
首先,人類處理和過濾信息的效率是有上限的,而至少目前看來,人類對計算機處理效率的開發還遠遠沒有接近上限。
第二,社交關係兩端的信息匹配是一種模糊、間接、多對多的匹配,而基於用戶數據的匹配則是一種直接、精準、一對一的匹配。
除此之外,智能媒體還有一項明顯的優勢,那就是,計算機沒有自利動機,不會濫用分發信息的權力。但是,「智能媒體」是否完美無缺呢?至少現在看來還很難這麼說。
儘管智能媒體的興起已經引起了全球範圍內的關注和模仿,但是目前,計算機還很難洞察人類信息和信息需求的深度和複雜度。曾經有某個頭條號發布了一篇關於「毛雞蛋」的文章,其實並不是在談論這種食物本身,而是表達一種帶有獵奇心態的青年亞文化。對於一個知道「毛雞蛋」是什麼的中國人來說,這一點並不難理解。但是計算機卻把這篇文章分類為「美食」——如果你告訴計算機,一篇寫滿了某種食物的文章其實和「食物」本身並沒有多少關係,至少在當下,她是很難理解的。
所以,在今天我們所處的階段,出現了一種相對保守但更接近人類習慣的媒體形態:「社交媒體」和「智能媒體」的交叉形態。「微博」在2014年底開始實施的「信息流優化計劃」,就是一種用「智能媒體」技術對「社交媒體」進行改造的實驗。
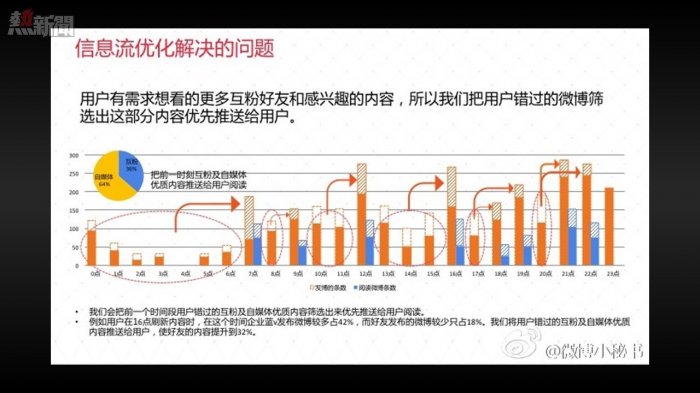
通過這種改造,微博把用戶信息流的排序從最原始的「時間排序」變成了「智能排序」,把用戶更有可能需求的信息提前、插入;而把「大V」們出於自利動機分發的無效信息從用戶的時間線上後置甚至移除。
這種改造在最初——就像大多數人類的新發明一樣——遭到了用戶的普遍抵觸。但是從微博收集的實際數據來看,這卻是一次成功的改造:實施1年以後,微博的人均閱讀量上漲了30%,轉發、點贊等互動行為增加了52%,信息流中的營銷信息則減少了62%。
在目前這個歷史階段,把「社交媒體」中人類的優勢與「智能媒體」的效率與公平性結合起來,也許提供了一種更平滑的過渡方式。

那麼,在未來呢?AlphaGo對李世石的勝利已經證明,在邏輯思考的效率上計算機已經更勝一籌。但是在感情、趣味、創造力等等更加複雜的方面,計算機也能代替人嗎?
其實這種可能性是很大的。計算機也許永遠不可能知道「愛情」是什麼樣一種感覺,但是,如果它注意到一個人開始增加在服裝、髮型上面的花費,開始頻繁增加和某位異性/同性的在線社交,她的心跳血壓開始經常出現某種異動,她開始不斷推遲回到家裡的時間……「智能媒體」大概就能在周五下班前,在某間氛圍浪漫的餐廳里,為她提前訂好兩個人的座位。
「智能」也許永遠不能像真正的人類那樣思考,但是如果有足夠多的數據、足夠快的運算力、足夠優秀的算法,「智能」的確能夠思考。
就像艾倫·圖靈所說的:「如果人們能夠接受思考方式的彼此不同,為什麼不能接受機器的思考方式和我們不同?」
從「雜貨鋪」到「人工智能」:現代媒體的技術演化











