





本文中的Big Data Landscape圖筆者隨手分享在LinkedIn上,不曉得引起大量轉發和評論,截止本周,得到6700個like,3800次share,400多條comment,筆者也覺得很神奇。這裡就跟從事大數據或者投資領域的朋友推薦一下。原文作者是VC First Mark的Mark Turck,提下這一家VC,主要投資於早期階段技術類公司的風險投資機構,包括新興媒體、廣告、遊戲、教育、雲計算、分析和基礎設備等方向。大家熟悉的Airbnb,Pinterest,Shopify都有它的投資身影。
技術型的高科技創業公司都是喜歡閃閃發光的新東西,而「大數據」跟3年前火熱程度相比反而有些凄慘。雖然Hadoop創建於2006年,在「大數據」的概念興起到達白熱化是在2011年至2014年期間,當時在媒體和行業面前,大數據就是「黑金石油」。但是現在有了某種高原感。 2015年數據世界中時尚年輕人喜歡轉移到AI的相關概念,他們口味變成:機器智能,深度學習等。
除了不可避免的炒作周期,我們第四次年度「大數據風水圖」(見下圖),回顧過去一年發生的事情,思考這個行業的未來機會。
2016年大數據還是「回事」嗎?讓我們深度挖掘。
企業級技術 = 艱苦的工作
其實大數據有趣的是它不是直接可以炒作的東西。
能夠獲得廣泛興趣的產品和服務往往是那些人們可以觸摸和感受到的,比如:移動應用,社交網絡,可穿戴設備,虛擬現實等。
但大數據,從根本上說是「管道」。當然,大數據支持許多消費者或企業用戶體驗,但其核心是企業的技術:數據庫,分析等:而這後面幾乎沒人能看到東西運行。
而且如果大家真正工作過的都知道,在企業中改造新技術並不大可能在一夜之間發生。
早年的大數據是在大型互聯網公司中(特別是谷歌,雅虎,Facebook,Twitter,LinkedIn等),它們重度使用和推動大數據技術。這些公司突然面臨著前所未有的數據量,沒有以前的基礎設施,並能招到一些最好的工程師,所以他們基本上是從零開始搭建他們所需要的技術。開源的風氣迅速蔓延,大量的新技術與更廣闊的世界共享。隨着時間推移,其中一些工程師離開了大型網絡公司,開始自己的大數據初創公司。其他的「數字原生」的公司,其中包括許多獨角獸,開始面臨跟大型互聯網公司同樣需求,無論有沒有基礎設施,它們都是這些大數據技術的早期採用者。而早期的成功導致更多的創業和風險投資。
現在一晃幾年了,我們現在是有大得多而棘手的機會:數據技術通過更廣泛從中型企業到非常大的跨國公司。不同的是「數字原生」的公司,不必從頭開始做。他們也有很多損失:在絕大多數的公司,現有的技術基礎設施「夠用」。這些組織也明白,宜早不宜遲需要進化,但他們不會一夜之間淘汰並更換關鍵任務的系統。任何發展都需要過程,預算,項目管理,導航,部門部署,全面的安全審計等。大型企業會小心謹慎地讓年輕的創業公司處理他們的基礎設施的關鍵部分。而且,一些(大多數?)企業家壓根不想把他們的數據遷移到雲中,至少不是公有雲。
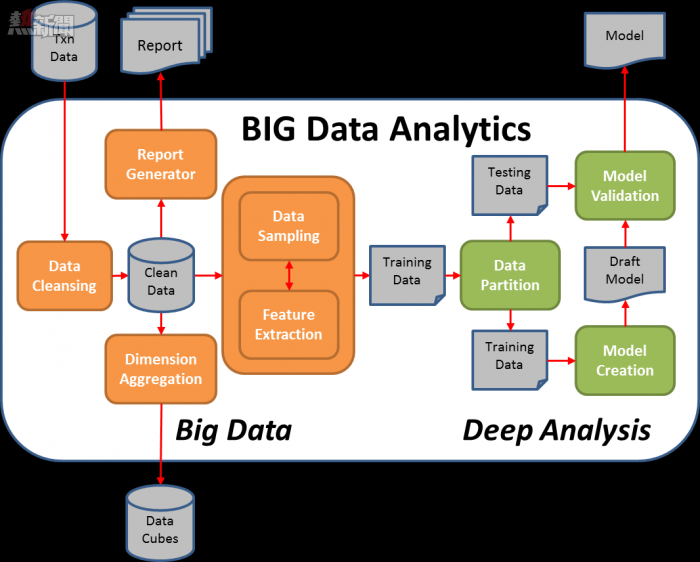
(大數據分析的基本流程圖)
從另一個關鍵點大家就明白了:大數據的成功是不是實現一小片技術(如Hadoop的或其他任何東西),而是需要放在一起的技術,人員,流程的流水線。你需要採集數據,存儲數據,清理數據,查詢數據,分析數據,可視化數據。這將由產品來完成,有些由人力來完成。一切都需要無縫集成。歸根結底,對於這一切工作,整個公司,從高級管理人員開始,需要致力於建立一個數據驅動的文化,大數據不是小事,而是全局的事。
換句話說:這是大量艱苦的工作。
部署階段
以上解釋了為什麼幾年後,雖然很多高調的創業公司上線也拿到引人注目的風險投資,但只是到達大數據部署和早期成熟階段。
更有遠見的大公司(稱他們為「嘗鮮者」在傳統的技術採用周期),在2011 - 2013年開始早期實驗大數據技術,推出Hadoop系統,或嘗試單點解決方案。他們招聘了形形色色的人,可能工作頭銜以前不存在(如「數據科學家」或「首席數據官」)。他們通過各種努力,包括在一個中央儲存庫或「數據湖」傾倒所有的數據,有時希望魔術隨之而來(通常沒有)。他們逐步建立內部競爭力,與不同廠商嘗試,部署到線上,討論在企業範圍內實施推廣。在許多情況下,他們不知道下一個重要的拐點在哪裡,經過幾年建設大數據基礎架構,從他們公司業務用戶的角度來看,也沒有那麼多東西去顯示它。但很多吃力不討好的工作已經完成,而部署在核心架構之上的應用程序又要開始做了。
下一組的大公司(稱他們為「早期大眾」在傳統的技術採用周期)一直呆在場邊,還在迷惑的望着這整個大數據這玩意。直到最近,他們希望大供應商(例如IBM)提供一個一站式的解決方案,但它們知道不會很快出現。他們看大數據全局圖很恐怖,就真的想知道是否要跟那些經常發音相同,也就湊齊解決方案的創業公司一起做。他們試圖弄清楚他們是否應該按順序並逐步工作,首先構建基礎設施,然後再分析應用層,或在同一時間做所有的,還是等到更容易做的東西出現。
生態系統正在走向成熟
同時,創業公司/供應商方面,大數據公司整體第一波(那些成立於2009年至2013)現在已經融資多輪,擴大他們的規模,積累了早期部署的成功與失敗教訓,也提供更成熟,久經考驗的產品。現在有少數是上市公司(包括HortonWorks和New Relic 它們的IPO在2014年12月),而其他(Cloudera,MongoDB的,等等)都融了數億美元。
VC投資仍然充滿活力,2016年前幾個星期看到一些巨額融資的晚期大數據初創公司:DataDog(9400萬),BloomReach(5600萬),Qubole(3000萬), PlaceIQ( 2500萬)這些大數據初創公司在2015年收到的$ 66.4億創業投資,占高科技投資總額的11%。
隨創業活動和資金的持續湧入,有些不錯的資本退出,日益活躍的高科技巨頭(亞馬遜,谷歌和IBM),公司數量不斷增加,這裡就是2016年大數據全景圖:
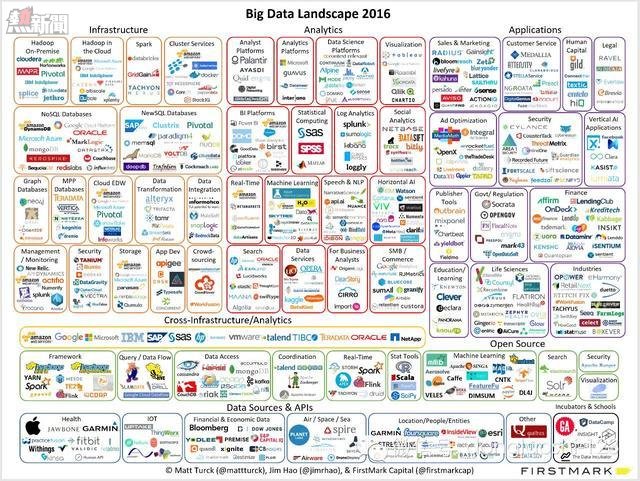
2016年2月12日修訂,(本文最有價值的圖)
很顯然這裡密密麻麻很多公司,從基本走勢方面,動態的(創新,推出新的產品和公司)已逐漸從左向右移動,從基礎設施層(開發人員/工程師)到分析層(數據科學家和分析師的世界)到應用層(商業用戶和消費者),其中「大數據的本地應用程序」已經迅速崛起- 這是我們預計的格局。
大數據基礎架構:創新仍然有很多
正是因為谷歌十年前的MapReduce和BigTable的論文,Doug Cutting, Mike Cafarella開發 創建Hadoop的,所以大數據的基礎架構層成熟了,也解決了一些關鍵問題。
而基礎設施領域的不斷創新蓬勃發展還是通過大量的開源活動。

(Spark帶着Hadoop飛)
2015年毫無疑問是Apache Spark最火的一年,這是一個開源框架,利用內存中做處理。這開始得到了不少爭論,從我們發布了前一版本以來,Spark被各個對手採納,從IBM到Cloudera都給它相當的支持。 Spark的意義在於它有效地解決了一些使用Hadoop很慢的關鍵問題:它的速度要快得多(基準測試表明:Spark比Hadoop的MapReduce的快10到100倍),更容易編寫,並非常適用於機器學習。
其他令人興奮的框架的不斷湧現,並獲得新的動力,如Flink,Ignite,Samza,Kudu等。一些思想領袖認為Mesos的出現(一個框架以「對你的數據中心編程就像是單一的資源池」),不需要完全的Hadoop。即使是在數據庫的世界,這似乎已經看到了更多的新興的玩家讓市場持續,大量令人興奮的事情正在發生,從圖形數據庫的成熟(Neo4j),此次推出的專業數據庫(時間序列數據庫InfluxDB),CockroachDB,(受到谷歌Spanner啟發出現,號稱提供二者最好的SQL和NoSQL),數據倉庫演變(Snowflake)。
大數據分析:現在的AI
在過去幾個月的大趨勢上,大數據分析已經越來越注重人工智能(各種形式和接口),去幫助分析海量數據,得出預測的見解。
最近AI的復活就好比大數據生的一個孩子。深度學習(獲取了最多的人工智能關注的領域)背後的算法大部分在幾十年前,但直到他們可以應用於代價便宜而速度夠快的大量數據來充分發揮其潛力(Yann LeCun, Facebook深度學習研究員主管)。 AI和大數據之間的關係是如此密切,一些業內專家現在認為,AI已經遺憾地「愛上了大數據」(Geometric Intelligence)。
反過來,AI現在正在幫助大數據實現承諾。AI /機器學習的分析重點變成大數據進化邏輯的下一步:現在我有這些數據,我該怎麼從中提取哪些洞察?當然,這其中的數據科學家們 - 從一開始他們的作用就是實現機器學習和做出有意義的數據模型。但漸漸地機器智能正在通過獲得數據去協助數據科學家。新興產品可以提取數學公式(Context Relevant)或自動構建和建議數據的科學模式,有可能產生最好的結果(DataRobot)。新的AI公司提供自動完成複雜的實體的標識(MetaMind,Clarifai,Dextro),或者提供強大預測分析(HyperScience)。
由於無監督學習的產品傳播和提升,我們有趣的想知道AI與數據科學家的關係如何演變 - 朋友還是敵人? AI是肯定不會在短期內很快取代數據科學家,而是希望看到數據科學家通常執行的簡單任務日益自動化,最後生產率大幅提高。
通過一切手段,AI /機器學習不是大數據分析的唯一趨勢。令人興奮的趨勢是大數據BI平台的成熟及其日益增強的實時能力(SiSense,Arcadia)
大數據應用:一個真正的加速度
由於一些核心基礎架構難題都已解決,大數據的應用層迅速建立。
在企業內部,各種工具已經出現,以幫助企業用戶操作核心功能。例如,大數據通過大量的內部和外部的數據,實時更新數據,可以幫助銷售和市場營銷弄清楚哪些客戶最有可能購買。客戶服務應用可以幫助個性化服務; HR應用程序可幫助找出如何吸引和留住最優秀的員工;等
專業大數據應用已經在幾乎任何垂直領域都很出色,從醫療保健(特別是在基因組學和藥物研究),到財經到時尚到司法(Mark43)。
兩個趨勢值得關注。
首先,很多這些應用都是「大數據同鄉」,因為他們本身就是建立在最新的大數據技術,並代表客戶能夠充分利用大數據的有效方式,無需部署底層的大數據技術,因為這些已「在一個盒子「,至少是對於那些特定功能 - 例如,ActionIQ是建立在Spark上,因此它的客戶可以充分利用他們的營銷部門Spark的權力,而無需實際部署Spark自己 - 在這種情況下,沒有「流水線」。
第二,人工智能同樣在應用程序級別有強大吸引力。例如,在貓捉老鼠的遊戲,安全上,AI被廣泛利用,它可以識別黑客和打擊網絡攻擊。 「人工智能」對沖基金也開始出現。全部由AI驅動數字助理行業已經去年出現,從自動安排會議(x.ai)任務,到購物為您帶來一切。這些解決方案依賴人工智能的程度差別很大,從接近100%的自動化,到個人的能力被AI增強 - 但是,趨勢是明確的。
結論
在許多方面,我們仍處於大數據的早期。儘管它發展了幾年,建設存儲和數據的過程只是第一階段的基礎設施。 AI /機器學習出現在大數據的應用層的趨勢。大數據和AI的結合將推動幾乎每一個行業的創新,這令人難以置信。從這個角度來看,大數據機會甚至可能比人們認為的還大。
隨着大數據的不斷成熟,這個詞本身可能會消失或者變得過時,沒有人會使用它了。它是成功通過技術,變得很普遍,無處不在,並最終無形化。
原文:Is Big Data Still a Thing? (The 2016 Big Data Landscape)
從大數據的風水圖,來看看Big Data是怎麼的一回事











