





虎嗅注:知乎已經走過了4年年頭,在互聯網的世界裡,知乎已經成為無可爭議的高質量社區,但在經歷了高速發展之後,如何管理,篩選,呈現這些大量的資訊(數據)成為一個難題,事實上無論對於哪一個社區而言,數據的管理本身就是一個巨大的挑戰。知乎是如何下面是知乎聯合創始人在七牛大會上的關於知乎數據方面的演講,虎嗅進行了刪減。
大家好,我是知乎的李申申。首先,我想對主辦方說一聲:謝邀!感謝你們搭建這樣一個專業的平臺,讓大家有機會聚在一起認真討論數據這個話題。
說實話,在接到大會邀請的時候,我第一反應想到了這句話。
Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it…- Dan Ariely .
如同Dan Ariely所說,知乎也像是眾多面對大數據很懵懂的「年輕人」之一;我們雖然也在做大數據相關的一些事情,但其實比較粗淺。我聽說今天在座的各位有不少都是知乎的用戶,對知乎有一些興趣,那我就借這個機會跟大家分享一下知乎數據方面的一些工作。
簡單進入正題,我們先來看看知乎的基本數據情況。
今天的知乎

截至2015年7月,知乎社區已擁有2900萬註冊用戶,月UV1.1億,月累積頁面瀏覽量達3億。現在知乎全站已累計產生約620萬個問題,以及近2000萬個回答。用戶總回答4,129,244,445字數,是大不列顛百科全書的近100倍,鹿鼎記的2580倍。
除了以上比較基礎的數據,一些其他方面的數字也在以令我們比較欣喜的速度發展著。我們截取了知乎開放註冊以來,獲得一千個以上讚同的回答和千字以上的回答兩個數據,看一下它們的增長情況。可以看到,這兩項數據都是保持了一個比較平穩的增長趨勢的。再看一下,這些用戶日均獲贊的數量。
首先,必須說明的是:我們並非完全將這兩項指標作為有價值回答的判斷標準,但是當用戶願意靜下心來花時間撰寫長文回答的時候,至少他的態度是認真的,也符合知乎所倡導的討論理念。另一方面,知乎上的千贊代表了1000位知乎用戶對此回答的認同和接納。除開2月份等過年過節的時期數據會略低些,其他時間,這一數據增速基本都保持在 10% 左右。
同樣基於話題這個維度,我們隨機抽取幾個話題看最近的用戶討論趨勢。
這裡展示的是心理學、互聯網、經濟以及天津爆炸這幾個話題。值得注意的一點在於,在天津爆炸事件席捲幾乎所有社交和輿論平臺,非常聚焦地引起爆炸性的關注時,知乎站內的其他專業話題討論依然在持續進行。同時,由於天津事件後續的各討論環節中有不少涉及心理學的疑問,因此,知乎站內心理學的話題熱度也被帶動著略有上揚。
綜合看,現在的知乎更像是個廣場,各類較為熱點的時事討論好像是廣場中央的噴泉,吸引了遊客和大眾的關注目光。而與此同時,在廣場四周也有著各色酒吧、咖啡館和茶館等,各自匯聚了城市的居民們與知己傾心交談。
知乎大VS知乎小白
有不少知乎用戶曾有疑慮,是否只有早期的用戶們才較為認同知乎的社區理念,又或是只有老用戶們容易收穫讚同和關注?其實並不盡然。
讓我們一起看看以下幾組數據截圖,橫軸為時間變化,我們截取了2010年12月20日知乎內測以來到2015年6月30日讚同數前10000的用戶,根據他們的註冊時間和讚同數作圖,以及日均的贊數增長量。大家可以看到這些點分佈的比較散,說明增長情況比較均勻。
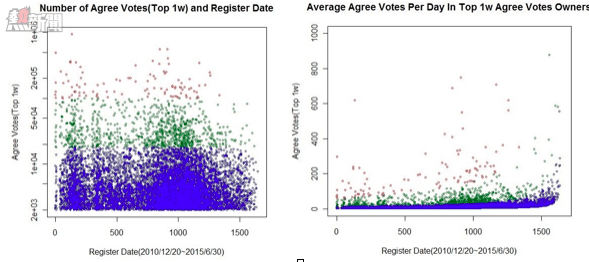
可以看出:即使在2015年才剛加入知乎的人也有非常大的機會被關注和認可。這也說明,這些新用戶也有認真討論、獲得有價值資訊交換的渴望,這些用戶也是非常認同知乎的社區理念的。可以通用的秘訣在於:只要堅持不斷地在自己擅長的領域參與討論、輸出資訊就能得到更多人的認可。
知乎資訊如何生產,以及如何流動?
前面幾張圖,我們已經瞭解了知乎的百花齊放的話題和持續貢獻的優質用戶。下面我們來看看知乎資訊生產方式,為了更聚焦的展示這個問題,我們選取了近期的天津爆炸事件作為事例。
從發展方式來看,熱點話題與其他話題相比,並沒有不同。但是由於其新聞性,這類話題的發展更具有爆發性,用戶的行為更為集中。因此,也更方便我們來做這樣一個展示。
首先,一批用戶針對問題進行關注、回答,產生了基礎的優質內容,然後,其他用戶的自發邀請、關注、收藏、感謝、投票、評論等社交行為,使得這些內容獲得了更廣泛的傳播和關注,覆蓋的人群不斷擴大。
在知乎,社交行為催生了優質內容的生產與傳播,而優質內容又引發了下一輪新的社交行為。
如何用大數據做用戶興趣識別?
用戶在知乎上的行為是多維度的;既包括比較輕的瀏覽閱讀,又包括重一些的讚同、反對,還有更重的提問回答(這裡的重和輕是根據用戶操作成本來界定的)。我們可以根據這些行為做用戶的特徵分析,這也是各個互聯網服務都會做的常規工作,只是基於各自不同的服務特點,所要分析的特徵、採用的演算法及其效果各有不同。知乎除了有大量的用戶行為數據,還有非常多的文本資訊,基於行為和文本,我們對用戶的興趣和擅長能有更準確的識別。
現實社會中,我們對於某些領域的知識掌握是很深入的,但其他的一些領域就未必了。個人精力是有限的,沒有人能夠全知到成為所有領域的專家,這種情況是可以被映射到知乎上的。不同的用戶在不同的話題領域下,他們的專業性是不同的,我們需要掌握這種不同,給每個人,在每個話題下計算一個權重。計算的分值最主要的依據還是那些你在知乎上的回答,當然,我們也會加入一些其他考量因素,包括其他專業人士對你的背書,你的專業背景,等等。
這是知乎非常基礎的數據設施,但這個數值計算的量級是不小的(百萬回答用戶十萬話題,是千億級別的數量計算),知乎對於權重判定每週都會進行全量的計算,也一直在調整優化中。
答案排序:如何更好的呈現?
我們對答案排序演算法進行優化,目的是讓好的答案更靠前。隨著用戶量不斷增加,早期最簡單的答案排序規則出現了問題:一些答案友情讚同比較多,讓專業性不足的答案被推到靠前的位置。我們想到了給讚同票加權重的方法,基於每個人在話題下的專業權重來計算,排序得到優化,能讓大部分優質答案可以排到前面。
雖然針對權重計算的優化仍然在持續進行,我們還是遇到了一些演算法上的瓶頸。
當問題下有多個發布較早的回答獲得高票時,新的回答即使質量很高,也很難在問題頁上獲得足夠的曝光,難以積累更多讚同票,一些誤導性、煽動性的高票內容,即使同時也有很多反對票,仍然排在認真、嚴謹但票數相對較少的優質回答前面。
這些問題在專業領域內對參與討論的用戶造成的傷害尤其明顯。這絕不是我們希望看到的。於是,我們又設計了新的排序演算法。
新排序演算法的思想是,如果把一個回答展示給很多人看並讓他們投票,內容質量不同的回答會得到不同比例的讚同和反對票數,最終得到一個反映內容質量的得分。當投票的人比較少時,可以根據已經獲得的票數估計這個回答的質量得分,投票的人越多則估計結果越接近真實得分。如果新一個回答獲得了 1 票讚同 0 票反對,也就是說參與投票的用戶 100% 都選了讚同,但是因為數量太少,所以得分也不會太高。如果一小段時間後這個回答獲得了 20 次讚同 1 次反對,那麼基於新演算法,我們就有較強的信心把它排在另一個有 50 次讚同 20 次反對的回答前面。原因是我們預測當這個回答同樣獲得 50 次讚同時,它獲得的反對數應該會小於 20。
威爾遜得分演算法最好的特性就是,即使前一步我們錯了,現在這個新回答排到了前面,獲得了更多展示,在它得到更多投票後,演算法便會自我修正,基於更多的投票數據更準確地計算得分,從而讓排序最終能夠真實地反映內容的質量。
我們的新演算法年初發布之後,得到知乎站內的用戶熱烈反饋,也算是做知乎這樣產品的好處吧,很多專業的討論湧現出來,為我們下一步優化提供了很好的想法。
首頁Feed的自我修養:內容的個性化推薦
首頁的內容會主要考慮這幾方面:
1、內容本身的話題領域要跟用戶有關,是用戶感興趣的,一個對汽車不感興趣的用戶,即便給他推送最優質的汽車內容,他也會覺得無趣。
2、知乎是一個社交網絡,用戶的社交行為會產生影響,用戶的行為會帶來關注他的人首頁的變化。
3時間因素,一些內容及時出現在你面前,可以讓它的價值更大
知乎的首頁有一套專用的數據收集和處理機制,可以記錄用戶在首頁的所有重要動作,比如,如果某條內容出現在用戶瀏覽器視窗或手機螢幕的可見範圍內,就會記錄一次。
以及……
知乎還有一些其他的數據優化,我舉幾個例子做簡單介紹。
邀請回答
稍微熟悉知乎的用戶,應該知道謝邀這個詞,這個產品功能是為每一個問題找到合適的回答者,推薦給用戶。我們採取一種演算法模型預測某個用戶回答某問題的可能性和回答質量。有 90% 的邀請是通過這種推薦結果發出的,剩下 10%是用戶主動搜索產生的
每週知乎精選郵件(eDM)
針對每個用戶做了個性化的計算,通過不斷的演算法優化,我們已經做到了30%的打開率和14%的點擊率。
問題聚類
眾所周知想對問題的文本進行聚類,最先想到的是通過文本語義匹配,通過複雜的詞袋模型(如傳統的plsa,LDA,新的word2vec等)對問題文本進行向量化,這樣通過語義將相關問題聚類起來。
知乎站內擁有龐大的用戶瀏覽數據,如果將這些瀏覽數據通過簡單地演算法(如協同過濾)建立一個模型同樣也能達到很好地效果。
知乎每天的問答瀏覽量能夠達到千萬級別,這樣就意味著輸入給演算法的user-item的邊數每天能夠達到千萬以上,近3個月的瀏覽數據就可以達到10億條邊。在知乎的數據平臺上需要近一小時的時間來建立模型,從聚類的結果中可以看出,即使不使用任何文本相關的分析,單靠用戶瀏覽的行為分析就可以很好地對問題進行聚類。
這也印證了一點:大數據基礎上的簡單演算法比小數據基礎上的複雜演算法更加有效。
From 虎嗅
知乎的另一面:如何用數據管理內容











