





編譯:元元、Chloe、朱顏夫、亭八
上周,在三星開發者大會(Samsung Developer Conference, SDC),出現了一個十分有趣的SDC展位,展位的主人是Gyroscope的團隊,他們為了在展台上呆兩天而不顯得無聊,做了一件事:他們讓Gyroscope的AI在超級任天堂上面征戰「街頭霸王2:究極格鬥」,期望通過與各個角色之間的搏鬥,讓Gyroscope學會格鬥技巧。
Gyroscope的AI並不會玩電子遊戲,他們的團隊也沒有超級任天堂的軟件開發包。所以在SDC大會之前,Gyroscope團隊先設法從「街頭霸王2:究極格鬥」中提取了遊戲信息,從而建立了Gyroscope的超級任天堂SDK。然後讓Gyroscope的AI與遊戲內置的計算機對手進行上千場的遊戲比拼,同時他們不斷地調整AI參數,讓它更加適應這個特殊的應用程序。
訓練AI
在訓練AI之前,首先要弄清楚究竟要解決什麼問題,Gyroscope團隊把「街頭霸王2」的問題抽象為強化學習問題。在強化學習問題中,AI要評估各種方案,選擇要採取的行動,最後獲得「回報」。但這一次AI程序的目標是根據過去觀察到的行為,採取最佳的行動,從而獲得最高的「獎賞」。所以在開始應用AI之前,Gyroscope團隊需要先定義「街頭霸王2」的觀察內容,換一個意思來講,就是要讓人工智能「看到」什麼,以及如何行動從而獲得某種「獎賞」。
觀察內容
觀察內容可以想象成AI在環境中「看到」的東西,比如人類觀察遊戲的時候,首先看到的是每個角色,以及角色的跳躍、移動、踢等動作,同時還能看到角色的血條與計時器,Gyroscope團隊需要把這些信息提取出來,轉化成AI可以理解的格式,這種格式通常被稱為「觀察空間」。
在強化學習中,觀察空間有兩種常見的思路,傳統的方法是測量人類認為與問題相關的具體信號;現代的方法是為AI提供每次行動後的全部環境圖像,讓AI決定圖像中的重要元素。現代的方法要比傳統方法更好,因為它有更好的普適性,不需要對特徵的重要性做過多的假設,但這種方法往往需要更長的訓練時間,因為時間的限制,Gyroscope團隊選擇了傳統方法,並手動定義觀察空間。
觀察空間被定義為:
• 每個玩家的X和Y坐標
• 每個玩家的血條
• 每個玩家是否在跳躍
• 每個玩家是否蹲伏
• 為每個玩家的動作編號
• 玩家之間X和Y坐標差的絕對值
• 遊戲時鐘
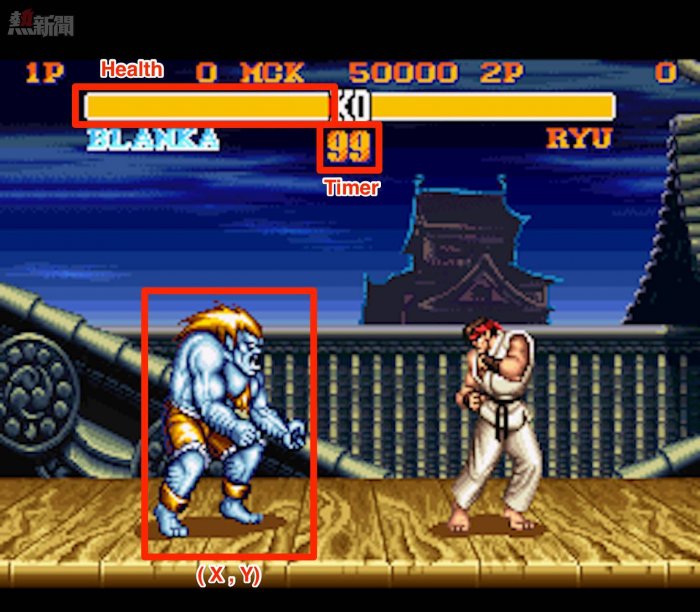
遊戲觀察空間示例,這個觀察空間不重複的觀察點達到了萬億甚至更多
行動
當AI觀察完環境之後必須採取行動,使角色行動起來最簡單的方法是採用超級任天堂手柄上的按鈕:上、下、左、右、A、B、X、Y、L、R。這幾個按鈕可以形成很多個按鈕組合,如果要考慮所有可能的按鈕組合,會產生1024(2^10)個可能的行動。這個可能的行動太多了,即使AI最終能夠學會,也需要訓練很長一段時間才能知道哪些行為有效,哪些不行,而且並不是所有的按鈕都可以隨時按下,許多動作要通過按鍵順序才能達到更好的效果。
基本動作
「街頭霸王2:究極格鬥」充分利用了CAPCOM搖桿和超級任天堂手柄。下面的示意圖包括8種基本控制的位置以及他們在遊戲中的用法。

方向控制(來自街頭霸王2:究極格鬥遊戲說明書)
從12點方法順時針:跳躍,向前翻轉,向前,進攻蹲伏,蹲伏,防禦蹲伏,防禦,向後跳躍。
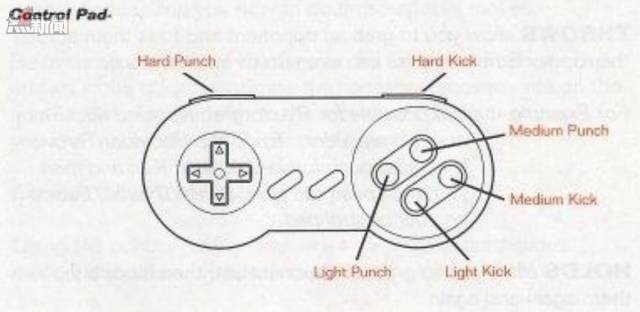
手柄按鈕控制(來自街頭霸王2:究極格鬥遊戲說明書)
從左上順時針:重擊,重踢,中等擊打,中等踢,輕踢,輕擊。
考慮到行動空間的另一個方向是一組動作,比如高踢、扔、勾拳等, 可以讓AI選擇一個動作,然後把這個動作轉換成一組按鈕。但確定一個角色的動作需要一段時間,不僅需要大量的查閱Google,還要自己親自玩,並且要對每個角色都要重複這個過程。
所以為了縮短訓練時間,Gyroscope團隊將動作空間簡化為一個按下方向控制和按下一個按鈕控制(例如「上+ A」或「L」)的組合,同時是否按下都是可選的,這一構建方法使得行動空間縮減成了35個可能的行動。更高級的動作和組合仍然可能隨着訓練時間的增加而出現,但是這部分留給了AI自行探索。
回報
最後,還要去思考這麼一個問題:一旦採取行動,AI是否就能收到回報?因為當人類玩遊戲的時候,會通過血條和傷害的大小,對遊戲目前的狀況大體上有一個認識。AI也需要通過一個數字的形式來理解遊戲狀況,讓它們使這個數字最大化從而獲得最佳獎勵,Gyroscope團隊選擇了每一幀的血條差距作為回報。
在每次觀察時,AI都會得到相當於玩家之間血條差距的獎勵。例如,如果AI通過踢動作使對方受到10點傷害,之後的血條差距將會是10點,AI得到同樣數量的回報。但如果AI在下次觀察後不採取行動,在「無」的情況下仍然得到10點,因為它保持了血條差距。相反的,如果AI被踢並且沒有防禦下來,則血條差距將會減小,所以這個差值也可能出現負的情況。
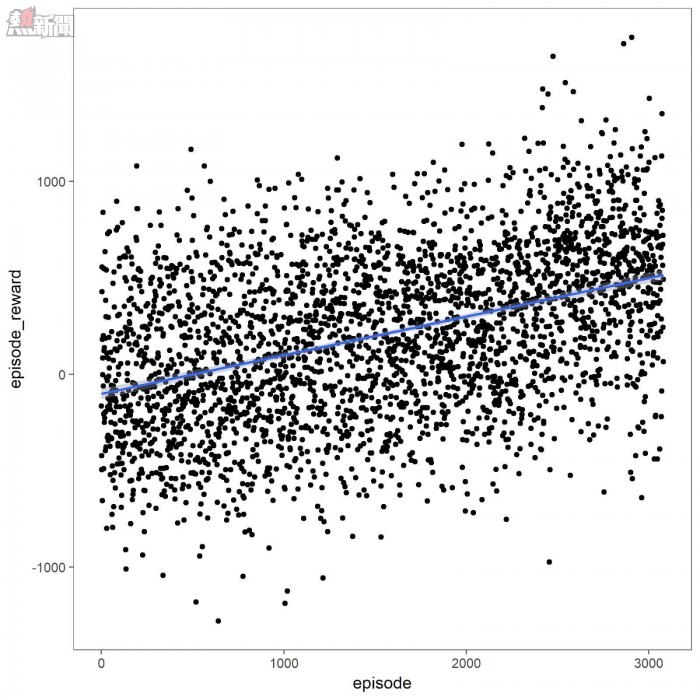
一場街頭爭霸比賽中Dhalsim(一個遊戲角色)得到的回報
創造人工智能的人工智能
以上是Gyroscope團隊討論的最終在比賽中採用的問題構建方法。同時Gyroscope團隊也調整了AI系統的參數,因為Gyroscope的自主AI是一個算法的算法,它可以找到每個問題適用的算法,而有了這麼多關於「街頭霸王」問題的信息之後,Gyroscope選擇深度Q網絡 (Deep Q-network, DQN)作為強化學習方法,同時也對DQN進行了一些修改。
值得一提的是基於圖像觀察空間缺失的修改:DQN使用模型來預測哪些行動最佳,而不是用窮舉法測試每個可能的行動。畢竟考慮到觀察空間的大小,探索每個可能的行動幾乎是不可能的。
模擬器連接
在訓練人工智能之前,需要先把它與街頭霸王連接起來,因為沒有超級任天堂的SDK,Gyroscope團隊在某個社區找到了一款連接經典遊戲機的工具,可以幫助他們測試超級任天堂的遊戲,從而使用AI技術來玩這些遊戲。
為了使AI連接到遊戲,不僅需要模擬器,還需要支持模擬器核心的工具。Gyroscope團隊找到了BizHawk,它可以支持多種模擬器核心,包括超級任天堂的核心。
BizHawk可以提供的重要功能:
• 一個Lua語言腳本界面,以便於逐幀控制遊戲;
• 一套控制台內存檢查工具,以便檢查遊戲內存(全部或特定地址);
• 運行中可以不受速度限制,也不需要顯示,從而最大化遊戲的幀率;
• BizHawk源代碼。
特別對於「街頭霸王」而言,Lua界面允許我們發送手柄按鍵信號,讀取按下按鈕信號,讀取存儲位置以及控制核心模擬器。內存檢測器可以讓我們獲取對手的血條情況、對手的動作以及其他觀察數據。
為了提高速度,Gyroscope團隊還將SDK代碼從Lua轉移到本地BizHawk工具,同時保留了之前寫的python代碼,他們把這些代碼命名為模擬器控制器。而為了能更好的控制遊戲和模擬器的方方面面,Gyroscope團隊還做了一個使用C#操作街霸的工具。
綜合起來:訓練AI

訓練初期,AI(圖中Dhalsim)隨機按下按鈕
定義好觀察結果、動作、獎勵值,再將AI連接到超級任天堂,就可以開始訓練它了。針對內置的遊戲機械人,每個角色大約訓練8小時或者3000場比賽。
Gyroscope團隊希望訓練好的AI將:
(1)最大限度地提高獎勵值,
(2)可以在訓練結束後擁有相當高的勝率。

訓練了3000場比賽後,Dhalsim積極進取,勝率50%
經過了觀察空間、動作空間、獎勵值函數和DQN參數的許多變體,最終得到了一個高勝率的AI。
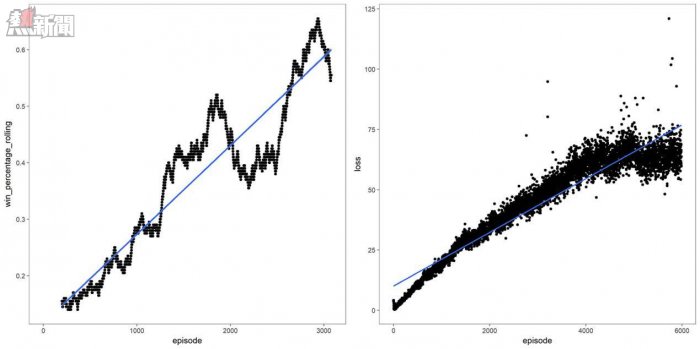
訓練期間的勝率和模型損失
除了標準模型調優技術和良好的科學原則(一次只改變一個量),Gyroscope團隊還有了一個重大發現:方向控制按壓與按鈕控制按壓的權重不同。方向控制只對一幀有效,在遊戲中影響很小;然而按鈕控制一旦按下,作用會維持一系列幀,在遊戲中影響重大。比如完成拳擊這一動作需要很多幀。這意味着在一幀內採取的動作會延續很多幀。
此外,雖然與方向控制按壓相比,按鈕按壓非常重要,但相應地也需要更加頻繁的按壓才能起作用。為了完成這一遊戲行為,也為了使AI行為更加人性化,他們讓AI在20幀(即1/3秒)內一直重複按鈕按壓,完後再採取下一個動作。換句話說,他們讓AI以1/3秒遊戲時間為單位來採取動作、觀察結果,而不是以每幀為單位。
至於Gyroscope團隊為什麼不用「獲勝」作為獎勵值。簡單來說,這樣做獎勵值是延遲的,會導致訓練更困難更耗時。
Gyroscope獲勝!

80%勝率;注意AI機智地攔截對方招數,還會瀟灑地走位
剛開始訓練的時候,AI隨機行動,對戰3星級對手(街霸採用星級評價體系)的勝率是20%。所以,20%勝率是底線,超過20%才能說明AI取得了成效。最後, AI對抗遊戲內置3星級機械人的勝率達到90%!針對比賽,取得80%勝率後Gyroscope團隊就停止了訓練,以避免過擬合。
AI獲勝後,Gyroscope團隊開始用街霸II的每個角色訓練它。為了訓練每個角色,他們使用Google雲端平台,寫了一些腳本進行全部的訓練,訓練需要通過一些腳本來自動完成玩家選擇、遊戲重置、模型記錄、進度繪製等功能。
會場上:戰鬥吧!

SDC上Gyroscope團隊的展位
會場上,Gyroscope團隊布置了展位來展示四場AI戰鬥,場場都是兩個AI控制的角色對抗。他們還畫了比賽樹狀圖——安排展位沒展示到的角色參加比賽。
第一天的比賽:M.Bison碾壓全場
四分之一決賽
Guile對戰Vega:Guile被吊打。Vega AI很快就學會了縮短距離,彎腰躲閃,刺向對方,並且還學會了神奇的走位,Vega勝出。
Blanka對戰M.Bison:M.Bison實力碾壓。他的獨門攻擊幾乎無法阻擋,就這樣M.Bison勝出。
Chun-Li對戰Sagat:Chun-Li也是近距離作戰——她的速度和近地攻擊打敗了Sagat的長距離襲擊和頻繁的走位。Chun-Li勝出。
Balrog對戰Dhalsim:十分有趣的是,Dhalsim幾乎一直在空中,用他的長腿攻擊Balrog。Dhalsim勝出。
半決賽
Vega對戰M.Bison:M.Bison的攻擊太猛烈了。M.Bison進入決賽。
Chun-Li對戰Dhalsim:Dhalsim在空中發起的進攻殺傷力非常大,輕鬆擊敗Chun-Li。
決賽
M.Bison對戰Dhalsim:由於M.Bison角色太過強大以至於無可匹敵,M.Bison輕鬆獲勝!
第二天的比賽:E.Honda攪動風雲

宣布E.Honda對戰Blanka
第二天,重新開始比賽,M.Bison從比賽中除名,因為它在夜裡私自使用興奮劑(作弊代碼)而被捕,Gyroscope團隊準備讓E.Honda加入,原因是它在測試時表現很差。
這天的戰鬥格外引人注目,Vega對抗Sagat打了一場持久戰,Vega靠近Sagat時,用神奇的走位至少躲過了三次Sagat的技能,一次是越過火球,兩次是拿準時間彎腰躲閃,但很遺憾的是,Vega依然輸掉了。
決賽是E.Honda對抗Sagat,當戰鬥到最後的時刻,兩個人物的血量都已經接近0了,但E.Honda出其不意的一擊,使其獲得了勝利。
Gyroscope團隊對E.Honda獲得勝利感到不可思議,他們認為E.Honda的運氣真的很好,因為他們又重新進行了100場E.Honda對戰Sagat的比賽,E.Honda只贏了11場而已。
學會了《街頭霸王2》的AI,你怕不怕?











