





虎嗅注:SerkanPiantino是FacebookAI研究工程部主管,Facebook紐約部主任。他在 Quora 回答了一些關於 Facebook AI 研究院的問題,新智元整理編譯了這些內容,虎嗅從中選取了一部分發布如下。
Q:FacebookAI研究院(FAIR)有哪些最有意思的項目?
有很多有趣的東西,但我會突出一些亮點,還有一些用途廣泛的、令人興奮的項目關鍵點。
首先,在感知方面,我們構建了能理解圖片、視頻、聲音等等外界輸入的系統。Facebook網站上也有一些示例,例如,我們構建了能夠回答圖片場景相關問題的系統,這裡是我們近期在參加MSCOCO挑戰賽時用於分割和標記物體的系統所生成的圖片。
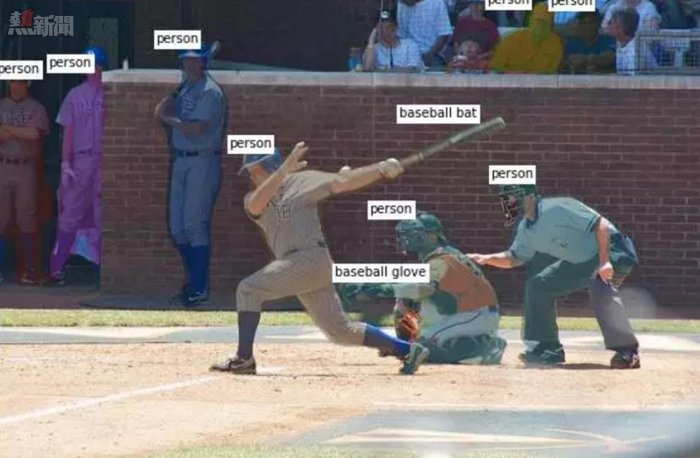


這類東西—完成了人類認知任務,如標記、對高維輸入(像素、視頻幀、音頻樣本等等)回答問題——近幾年被廣泛地使用,特別是使用了卷積神經網絡這類技巧後。卷積神經網絡是我的同事YannLeCun很早以前發明的,後來因為GPU處理海量數據的強大能力而變得很實用。這很令人興奮,因為它的進步速度十分快,而且這也開闢了以往沒有的新產品領域——能夠在Facebook上理解文本和意圖的產品領域。
我們也開始逆嚮應用這些網絡,讓它們從一段文字描述中想象場景或圖片,而不是從圖片中總結出文字。以下是FAIRySoumithChintala和波士頓的indicoResearch的一些合作成果,它生成了AI自己想象出的卧室場景。

而且這些網絡也被用於生成面部圖像、專輯封面、花、中國漢字甚至還有二次元角色圖像。
下一件我想突出的事情是我們賦予這些網絡類似於人類記憶和推理的能力。FacebookM項目中一些自動化部分是依靠記憶網絡的,這一工作是被FAIRy的JasonWeston發表出來。為了處理長對話,我們不得不理解每段文本的意思,而且為了我們以後也能查詢這些內容,我們也需要存儲和訪問它們。這些記憶網絡是在時間中學習如何創造並查詢既定事實的一系列網絡構建方法的一部分。如果說我們傳統而無狀態(stateless)的方法看起來像是在時間的推移中學習構建簡單電路的話,那麼這些網絡看起來就像是完全的自主布線處理器(full,self-wiringprocessors)。我們也有一些關於這種網絡讀故事並隨後回答問題的網絡示例。
最後,我們從Facebook本身也學到很多東西。Facebook有15.5億用戶,他們之間的相互聯繫和對外部世界的發掘給了我們絕佳機會來研究人類。作為一名工程師,將系統擴展到整個Facebook社交圖上並從中學習讓我非常興奮,而全球唯一能夠做到這一點的地方就在這裡。我們還有很遠的路要走,但我們希望在工作(預測和理解Facebook社交關係圖)中學到更多關於人們的東西。
這無論如何都不是所有的有趣研究,但是它們是我個人喜歡的一些亮點。
Q:在接下來的5年裡我們預期會看到哪些AI產品?
現在有很多神奇的產品,但現在大部分產品所具有的能力是很原始的。這些產品正用很多種方式轉化為Facebook的產品,但是我們需要做更多才能將這些技術挖掘出來,進而將人們天馬行空的想象轉化為真實的產品。現在,一些AI公司太貪心科技研發以至於他們沒有發布任何東西。
所以,接下來的5年裡,很多我們在研究社區中討論過的東西預計會變成更加普及和商品化的技術,也會有很多新初創公司(還有我們的團隊)盡他們所能來用AI改善生活。
Q:相比百度AI或谷歌AI,FacebookAI有哪些優勢?
我認為有一些結構方面的優勢:
·我們已經特別擅長硬件、軟件、開發平台和基礎設施的建設來加速團隊工作效率;
·我們有全球最大的跨文化、多模態、結構化、有組織的人們互動的數據庫;
·我們100%承諾會用5到10年時間來開拓AI領域,而且開源並發表我們所有的技術以供行業使用。
Q:讓一個遠程團隊變得積極、緊密聯繫並有高生產力有哪些好方法?
這裡是一些技巧:
團隊結構很重要。分情況對待,遠程團隊中的單獨個體感到受挫的頻率以天為計算單位;需要遠程管理的一小波人所組成的團隊感到受挫的頻率以周來計算;遠離主管或其他機構領導的一個完整團隊感到受挫的頻率以月計算;一個完整的機構,還具有自主性、遠見和決策制定有可能永遠也不會感到受挫;
人們需要周期性「全面同步」,特別是在關鍵時期,例如做出了一些決定或某些計劃被合併了。這些同步之間不能相隔太久,否則有可能存在風險,如團隊成員做錯事或沒在相同的節奏上;
遠程管理會感覺十分陌生而且具有強制性。你需要嘗試拜訪你的團隊,再三確定他們是決定製定過程和組織變化過程的一部分,因為如果你不這樣做,他們傾向於將這些看做是公司總部的強制命令(這會讓人感受到封閉);
僱員旅行訂票時不要有冗長的條條框框,鼓勵他們經常旅行。他們比你了解應該何時到目的地更好。
強調他們的自主性,並保護它。如果他們感受到你的信任的話,他們會給你驚喜的。
Q:如果讓你告訴那些對AI十分感興趣的初學者一件事情,它會是什麼?
現在這一研究社群有很多興奮的進展,因為一直有新的發現被公布,基準測試結果被不斷刷新。但是你不需要發明一些新的東西來從事AI工作。你需要複製這些成功的工具都是開源的,而且很有可能你想要的網絡在Github上是開放的,而且是預訓練好並隨時可用的。
查看一下代碼;鼓搗一下模型看看會發生什麼;在社群中問問題。這個領域需要更多的實踐者,和更多的人來將這些發現變為有用的產品。
Q:今天最富有挑戰性卻最簡單的AI問題?
非監督學習。
我們今天構建的幾乎所有的東西都被我稱為專業AI。我們有某個任務的足夠樣本,接着我們訓練電腦在沒有我們的情況下完成任務。在我們的AI示例中沒有顯示出來的一件事是我們在人力標記圖片、標記視頻數據集等等方面花費了多少精力才讓機器得到了足夠數據來學習完成某個任務。
人類真的不是這樣學習的。我們能夠通過看、感知和體驗現實來理解世界並在世界中進行活動。如果我們想要造出類似通用AI的東西的話,我們要弄清楚如何從簡單的觀察中進行學習。換句話來說,我們要開發出一個不需要人類標記來「監督」的系統。
我不認為有人真正破解了這個問題,雖然有很多人嘗試,而且我們的模型和電腦要想成功處理這類問題,有可能還要變強大10或100或1000倍。
Q:Facebook會開發和/或開源深度學習專業硬件嗎?
我們最近的硬件設計就是這樣做的,名為「BigSur」。
Facebook AI 研究院負責人:相比百度和谷歌,我們有哪些優勢?











