





本文來自Popsci.com,由機器之心編譯:
是時候停止把Facebook當作純粹的社交媒體公司來看了。它用無人機提供互聯網服務,為了發展虛擬現實而收購Oculus,不懈追求人工智能,Facebook已經迅速成為世界上最先進的技術研究中心之一了。
無獨有偶,Google甚至IBM之類的公司也有類似的計劃,總的來說,人工智能領域的發展已經提速到無疑會影響到人機交互的節點了。事實上,這已經發生了,不過是悄悄地在幕後進行。每月為15億用戶提供服務的Facebook對人工智能技術興趣濃厚。Facebook解決的是模擬一般智力的問題——即讓計算機日漸脫離線性邏輯的機器的思考方式,而是像我們自由形態的人類以多管齊下的方式來思考。Facebook人工智能研究室(FAIR)致力於解決廣義的人工智能的問題,而語言技術項目組和Facebook M(虛擬助手)這類規模稍小的項目組則致力於開發用戶操作中會用到的實際功能。
Facebook人工智能研究室的誕生
一切始於2013年,Facebook創始人兼CEO Mark Zuckerberg、CTO Mike Schroepfer和其他公司高層在評估公司上線十年以來的成就,並思考在接下來的十年、二十年如何長盛不衰。
Facebook已經將機器學習運用到其流行的社交網絡中,比如說決定用戶會在News Feeds中看到什麼內容。不過相比起當時前沿的神經網絡成果,這不過是小兒科。
一些Facebook工程師也一直在嘗試積卷神經網絡(CNNs),這是一種非常強大的機器學習,現在普遍被用於圖像識別。 即便人工智能還處於發展初期,Zuckerberg對它的潛力非常看好,因此他從Google大腦(Google Brain)挖了一位叫做Marc Aurelio Ranzato的工程師。然後他追本溯源找到了積卷神經網絡的發明者——Yann LeCun。
Facebook人工智能實驗室負責人Yann LeCun是人工智能界的一個傳奇。他最早在1988年在貝爾實驗室擔任研究員(由電話之父Alexander Graham Bell創立,並因其在電信技術領域的無數領域的實驗而聞名)開始他的研究,然後在AT&T實驗室擔任部門主管直到2003年。那之後他開始在紐約大學任教。現代的卷積神經網絡是 LeCun職業生涯的巔峰之作。你是否曾經好奇過ATM怎麼能識別你的支票?這就得益於 LeCun負責的「SN」的神經網路模擬器的早期研究,於1996年被採用。
「我開始和Schroepfer 和Mark接洽,我想他們也許喜歡我向他們講述的東西」,LeCun在接受《Popular Science》採訪中說道:「他們試圖說服我來運作這個實驗室……當像Mark 那樣的人跑過來和你說:『好吧,你基本上接受了全權委託。你能組建世界一流的研究室,我希望你建立起全世界最好的人工智能研究實驗室』。我的回答將會是:『嗯,相當有意思的挑戰。』」
關於世界頂級的研究室是什麼樣子,Yann有自己的想法。如果你想要吸引頂尖人才,你得有一個雄心勃勃的研究室,有着雄心勃勃的長期目標。然後你還得給他們工作上的自由權,同時對你的研究你必須持有非常開放的態度。「這和Facebook的信念有幾分吻合,Facebook秉持着開放的理念。」LeCun說。
組建團隊
這個肩負着Facebook的未來的團隊規模很小,由大約 30個研究科學家和15名工程師組成。團隊有三個分支:Facebook人工智能研究組的主要辦公室位於紐約市的Astor Place,由LeCun管理着一個由20名工程師和研究人員組成的團隊。Menlo Park的是一個同等規模的分支。六月,FAIR又在巴黎設立了一個更小的5人組,與INRIA(法國計算機科學與自動化研究機構)合作。還有很多在Facebook其他部門一起合作致力於人工智能發展的團隊,例如語言技術團隊;FAIR只是主要的研究部門。
這些研究人員和工程師來自科技領域的各個層面,同時當中很多人都曾與Lecun合作過。高等級的人工智能研究並非是一個龐大的領域,而且Lecun的很多學生都創建了人工智能方面的初創公司,它們一般會被像Twitter這樣更大的企業收購。
Lecun曾經告訴《連線》雜誌,「深度學習實際上是Geofff Hinton,我,還有蒙特利爾大學的Yoshua Bengio之間的一個陰謀。」 Hinton在Google研發人工智能, Bengio奔波於蒙特利爾大學和數據挖掘公司Apstat之間,而LeCun也與其他行業內的著名企業有千絲萬縷的關聯。
「當我第一次在貝爾實驗室做到部門主管時,我的老闆對我說,你需要記住兩點:首先,永遠不要讓自己陷入團隊內部的競爭。第二,只傭用那些比你更聰明的人,」LeCun說。
負責領導語言研究子群的Leon Bottou,是LeCun的一個老同事。他們一同研發了神經網絡模擬器,1987年的AmigaOS就是他們的第一個作品。Bottou 2015年3月加入的FAIR,此前他在為微軟研究組工作的同時,還致力於機器學習和機器推理的探索。

從左數起,Leon Bottou, Yann LeCun, 還有Rob Fergus,在Facebook的紐約辦公室裡工作
2014年11月,LeCun請來 Vladimir Vapnik作為他們的團隊顧問。Vapnik和LeCun曾一起在貝爾實驗室工作,發表了關於機器學習的形成性研究,其中包括一項測量機器學習能力的技術。Vapnik是統計學習理論之父,統計學習理論即基於既定數據的預測。預測,對人類來說似乎是一個簡單的任務,實際上卻需要關於預先形成的概念和對世界的觀察的海量信息(更多是後者)。Vapnik,這一領域的先驅,基於他在知識傳播上的興趣,繼續着這一領域的工作,並把師生互動時的線索運用在機器學習當中。
目標
團隊的規模和科研力量允許Facebook擁有雄心勃勃的長期目標,絕不會達不到被LeCun稱為「明確的智慧」的標準。
「迄今,最好的人工智能系統也是愚鈍的,因為它們沒有常識。」LeCun說道。他用一種情況舉例,比如我拿起一個瓶子,然後離開房間。(我們在紐約Facebook的會議室裡討論真正的機器智能的誕生,而這個房間的名字卻不怎麼吉利—— Gozer the Gozerian,與《捉鬼敢死隊》裡面的反派同名。)人類的大腦不難想像出一個人拿起瓶子然後離開房間這麼個簡單的場景,但對一台機器來說,僅這個前提就會導致大量的信息缺失。
Yann一邊說,我一邊在心中想像這個場景:「你很可能站起來,即使我在語句中沒有提到,你也很可能走動;你打開門,走進去,也許還會關上門;瓶子不在房間裡。由於知道真實世界的情況和界限,你可以借由判斷。因此我並不需要告訴你所有的細節。」
現在對於機器如何學習該水平的推理,人工智能領域的專家知道得並不多。在向這個目標邁進途中,Facebook正致力於製造能足夠好地學習已知世界的機器。
LeCun說:「最大的障礙是自助式學習(unsupervised learning)。」現在機器主要通過一兩種方式進行學習,即他助式學習(supervised learning)——在系統中,向機器展示成千上萬的狗的圖片,直到機器了解了狗的特徵。Google的DeepDream以研究者反轉流程以揭示出其有效性對這一方法進行了闡釋。
另一種方式是增強學習(reinforcement learning),即機器對給出的信息以是或否的二擇一的方式進行選擇,以給出一個答案。這種學習耗費的時間稍長,但是機器被強制由自身做出內在的抉擇。當這兩種學習方式結合起來時,就會產生強大結果。(還記得DeepMind Atari嗎)。自助式學習不需要反饋或者輸入,LeCun表示這就是人類的學習方式。我們發現、得出結論,並將其加入到人類的知識庫存之中。這,被證明是一項艱巨的任務。
LeCun笑着說:「我們甚至沒有一個用以發展人工智能的基本指導原則,很明顯,我們在努力尋找。我們有很多點子,只是目前沒一個奏效罷了。」
真正人工智能的早期探索
但是這並不是說以前的探索沒有成果。現在讓LeCun激動的是關於」記憶網絡」的工作,其可以被整合進積卷神經網絡,並使它們獲得記憶保持的能力。LeCun把這個新的記憶模型比作大腦中的分別由海馬體和大腦皮層控制的短期記憶和長期記憶(LeCun厭惡把CNNs比作大腦,相反他更喜歡這個模型:一個帶有50億把手的黑箱)。
記憶單元允許研究者向該「記憶網絡」講說一個故事,隨後使該網絡回答關於這個故事的問題。
故事選自《指環王》一書。我們不把全書而是書中主要情節的簡短概述(「比爾博拿到了魔戒」)講給「記憶網絡」,當被問及在書中某一具體情節中魔戒在哪裡,這個「記憶網絡」能做出簡短正確的回答。Facebook 熟悉科學官Mike Schroepfer說(他強調技術可以幫助Facebook以更高的精確度向人們展示其想看到的)這意味着它理解書中事物與時間的關係。
「通過搭建能理解世界的本質、了解你所想要的是什麼的系統,我們就能幫助你。」 Schroepfer在三月的一個開發者報告會上說道:「我們能搭建出一個系統,確保讓所有人可以把時間花在他們真正關心的事情上。」
FAIR團隊正在圍繞這個目標開發一個被稱為「嵌入世界」的項目。在該項目中,為了幫助機器更好的理解現實,FAIR團隊正在教它們用向量表示所有事物之間的關係,如:圖像,帖子,評論,相片及視頻等之間的關係。神經網絡也在構建一個包含了能組合媒體內容、不同個體之間的距離等錯綜複雜內容的體系。
嵌入世界
Lecun說通過使用這一系統能讓我們開始「用代數替換原因」。這表示着讓人難以置信的強大。在嵌入世界項目中開發的人工神經網絡能夠根據視覺相似性將在同一地點拍攝的兩張不同照片連接起來,並能指出文字描述是否符合場景。它重建了現實的一種虛擬記憶,並將之在其他地方和事件的背景下進行聚類。它甚至能根據一個人之前的喜好,興趣以及數字經歷「虛擬地表示這個人」。雖然這還只是帶有實驗性質的,但是對Facebook 的新聞流呈現具有很大的影響,在跟蹤標籤上也進行了一定的使用。
有很多關於長期目標的演說,但恰恰是小的勝利讓Facebook不斷前行。在2014年6月,他們發表了一篇名為《DeepFace:縮小人類表現與人臉識別間差距》的文章,該文宣稱在Facebook的這項技術在人臉識別中已達到97%的準確率。Lecun說:他相信Facebook的人臉識別技術已達到世界第一,這也是Facebook與學術研究機構的一個關鍵性的區別。現在,DeepFace是Facebook自動標記照片背後的驅動力。
「如果我們有一個切實有效的想法,我們就能讓它在一個月內出現在15億人面前。」LeCun說,「讓我們把目光聚焦在我們的長期目標的高度上,但是,在這個過程中會有很多我們將要去實現的會在短期具有實用性質的事。」
作為FAIR的研究成員之一的Rob Fergus(右站立),正在紐約辦公室處理有關人工智能虛擬方面的工作
作為在NYU和MIT計算機科學和人工智能實驗室工作過的老手,Rob Fergus領導着有關計算機視覺的AI團隊。他們的工作已經在自動標記相片上得到使用,接下來將被用於標記視頻。大量視頻因為缺乏元數據,或者沒有任何描述性文本,而被「淹沒」於噪聲中。AI將會能夠「觀看」視頻,並將它們大致分類。
這對Facebook阻止那些不想被上傳到他們服務器上的內容具有巨大的意義—例如色情照片,版權問題或者其他違反他們使用條款的任何內容。它也能鑒別新聞事件,對不同類型的視頻進行管理。Facebook此前一直將這些任務劃分給外包公司,當這項技術穩定後,Facebook就能降低這部分的人工成本。
在目前的測試中,人工智能表現得很有希望。給它播放一段正在進行的體育視頻,比如冰球、籃球或乒乓球,人工智能能夠準確地識別出這個體育項目。並且還可以區分壘球和棒球,漂流和皮划艇,以及籃球和街球這些類似的運動。
Facebook背後的人工智能
Facebook有一個叫做語言科技的獨立小組,主要負責開發翻譯,語言辨識和自然語言理解。LeCun所在的部門,Facebook人工智能研究室(FAIR)是Facebook人工智能戰略研究的主力,而語言科技(從屬於應用機器學習)是實際進行軟件開發的地方。
他們與FAIR合作,但獨立進行開發和實踐,並且已經開發了493種廣泛使用的翻譯方向(從英語到法語,從法語到英語算兩種方向)。
本着讓世界更開放更連通的宗旨,語言服務是Facebook的一條必經之路。超過一半以上的Facebook用戶不說英語,然而Facebook上大部分的內容都是通過英語呈現的,語言科技小組的負責人Alan Packer說道。
約有三億三千萬用戶經常點擊「見翻譯」按鈕使用這些翻譯服務。
如果你是第一個點擊翻譯按鈕的人,恭喜,你已經操作了人工智能了。首次點擊會向服務器發出翻譯請求,之後該請求將存儲起來供其他用戶使用。Packer說,夏奇拉(Shakira,著名拉丁裔歌手)發布的內容總是很快就翻譯出來了。語言科技小組還推出了本地內容翻譯,通過點擊「見原文」按鈕可以體驗這項服務。
人工智能是這項任務裡一個必要的環節,因為「傻瓜」翻譯對於人們彼此之間相互溝通作用不大,還會生成不正確的語法,誤讀的習語,俚語也無從參考。這就是過去Google翻譯那種直接逐詞翻譯的缺陷。
Packer說,修辭尤其難翻譯,但人工智能可以把握一些語義層面的含義。
「如果把『熱狗(hot dog)』這個詞組按字面翻譯成法語,是說不通的。『Chaud chien』對法國人來說沒有任何意義,」Packer說道。「同樣如果你拿着一幅我滑雪的照片,我說,『我今天秀了一下滑雪技巧(I』m hot dogging it today),』這就變得很難理解,因為這裡的hot dogging是炫耀的意思。」
儘管這種理解並不算太多,但早期的結果預示着這個任務很難處理。Packer說,人工智能的妙處在於它不會去理解比喻或習語,但仍會在不理解的同時認識到這一點。
人工智能本身具有適應性,經過訓練後便可以很快掌握俚語。語言科技小組最近發現法國球迷在用一個新俚語表達「wow」,人工智能在接受那部分公用數據的神經網絡訓練以後,現在能夠可靠地將文本翻譯出來。他們通過每天對人工智能進行新數據的訓練擴展Facebook的詞庫,不過所有語言的詞庫正在按月更新。
Facebook M
我們已經習慣於個人數字助理,比如Siri,Cortana,以及Google Now。但Facebook選擇了一條不同的道路,其名為「M」的新型個人AI助理擁有超越手機界限處理複雜事物的能力。Siri可以發短訊,而M可以預定航班或制定旅行計劃。在開發過程中,一位Facebook的僱員甚至讓M安排了一個找搬家公司到家中進行評估的日程。(不過當然了,你不能讓M給你買煙草、酒、槍支,或者給你安排色情服務。)
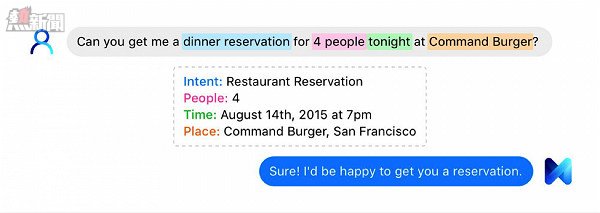
在三年內,M有可能能夠給有線電視公司或者車輛管理部門打電話,並幫用戶在線等待,直到對方的接線員接過電話。
事實上,Facebook M的主幹來自於今年早些時候收購的一家創業公司:Wit.ia。他們加入了Messenger的小組,受VP David Marcus的管理,並在本月早些時候首次發布了M。
Alex LeBrun在Facebook內部領導Wit.ai小組,他說人工智能不僅幫助M更好地完成一般的任務,也能完成有一些特殊情況的任務,如帶一個小嬰兒旅遊,或在燈火管制日的時候旅行。這也意味着M的能力隨着人工智能的發展而發展。他樂觀地認為,在三年內,M就可能有能力呼叫有線電視公司或者車輛管理部門,並幫助用戶在線等待,直到有人接過電話。
「M這樣的服務最大的附加值在於它能夠完全滿足你的需求,甚至在你的需求比較特殊或比較奇怪的情況下,」 LeBrun 說,「在任務比較複雜或並非常理情況的時候,它也能完成任務。」
隨着M的運行,它能夠不斷學習。現在,它還沒有能力獨自運行。一個被稱為「AI訓練者」的小組跟M一起工作,如果出現M不懂的任務,小組會接管過來。隨後M可以從人類訓練者身上學到應該怎麼做,並應用到之後的任務中。在程序中還內嵌了一種隨機機制,Lebrun說是為了讓它更像人類學習的過程。
「AI訓練者」是個新的職位,Facebook本身也在對這個職位的探索中。他們說,這並不是一個給研究員或者工程師的職位,而是為那些擁有客戶服務經驗的人準備的。Facebook將能夠評估哪些任務需要人類的干預,但最後,他們希望在未來完成這些任務將不需要任何人類干預。
但在開發過程中,這個職位是必須的,因為他們的工作主要有兩部分:一是保證服務質量的最後一道關卡,二是訓練AI。
有人類智能做看門人,M可以在FAIR進行開發時當做沙盒來用。「如果有什麼東西需要測試,就會在M中顯現,因為在我們的訓練和督導下,這個過程是沒有風險的。」Lebrun說。
M平台是完全建立在Wit.ai的平台之上的(主要在Facebook收購前就已研發),但FAIR也會對用戶和個人AI助理的交互過程產生的數據用作深度學習。
Facebook在人工智能團體中的角色
「我們的研究項目都是完全公開的。幾乎我們做的每件事都會發布,大部分的代碼也都是開源的」 LeCun 說道。你可以在 Facebook 的研究網站上和 ArXiv——一個收納電腦科學、數學及物理研究的圖書館,找到這些出版物。
大多人工智能團體都是這樣不隱秘的。 LeCun 已成為發展 Torch(一個針對AI 發展的C++算法庫)的領軍人物。LeCun帶領他的團隊,還有 Twitter 和 Google的 DeepMind 的研究人員合作,共同發展 Torch。許多現今在這個領域的專家都曾是LeCun的學生。
任何他們可能出版的資料,從與醫學成像相關的資料到無人駕駛車,也都是公開以促進未來發展的,LeCun說道。Facebook的研究固然對他們的用戶很重要,但它的核心價值更佳體現在讓人類對如何更好地用機器來模仿智能的知識。
這是為什麼Facebook是人工智能社區中重要的一部分,也是為什麼這個社區本身是如此重要。
「那些你在荷里活電影裡看到的情節,譬如一個在阿拉斯加與世隔絕的人研究出了完美運作,並在當下無人企及的人工智能系統,是完全不可能的」。LeCun說,「這是當代最大最複雜的科學挑戰之一,沒有任何一個人,甚至一個大公司能夠憑他們自己解決。解決它需要整個研究發展社區的集體力量」。
Facebook如何使用「我們」的數據去構建人工智能











