虎嗅注:當李開復還在穀歌的時候,他對搜尋引擎的語音識別功能就非常著迷。幾年過後,百度終於做了一個拿得出手的普通話語音識別模型,以及它背靠的深度學習系統Deep Speech。本文是SCALE記者對百度高級工程師Awni Hannun進行的專訪,Hannun談論了Deep Speech的特點、普通話語音識別的難點,以及對深度學習(Deep Learning)未來的展望。原文來自Medium,標題為《Baidu explains how it』s mastering Mandarin with deep learning》,由虎嗅編譯。
8月8日,國際神經網絡協會(International Neural Network Society)在美國舊金山召開大數據會議。會上,百度的高級研究工程師Awni Hannun向大家展示了一個新的語音識別模型,由百度研發用以識別普通話語音檢索。這個語音識別模型基於百度在2014年12月發布的深度學習系統Deep Speech,並在測試中達到94%的正確率。
在這個稍經編輯的採訪中,Hannun將解釋這個研究成果的重要性、為什麼普通話是一種很難學習的語言,以及深度學習將對我們的未來產生怎樣的影響。
關於Deep Speech
Q:Deep Speech在翻譯普通話時的準確性如何?
Awni Hannun:有6%的錯誤率,也就是說在100個字中會有6個錯字。如果放到語境中,我認為這是辨識普通話語音檢索的工具中最好的一個系統(我們的研究數據也這樣顯示)。
事實上,我們做過一個實驗。在我們的實驗室裡有幾個會講中文的人,他們將我們用以測試系統的語音進行人工識別和轉錄。結果顯示,如果我們不讓被試者使用網絡或其他一些工具,系統的轉錄效果要比人工的好。
「我們提供足夠多的數據,在盡可能少的人為幹預下,讓系統得以辨別與輸入相關的資訊,並正確輸出轉錄結果。」
Q:為什麼普通話的語音識別相比其他語言要難得多?
Awni Hannun:普通話和其他語言有幾個區別,以至於我們的英語語音系統難以適用於這種語言。首先,這是一種有音調的語言。如果你用不同的音調說一個詞,它的意思可能完全不一樣了,這和英語完全不一樣。在傳統的語音識別中,音調的不變性很重要,也就是說系統在轉錄語音的時候,會忽略音調。所以,為了進行普通話(或其他中文語言)語音識別,你必須更改很多系統設置。

Awni Hannun
但是,對我們來說,我們也不需要改變那麼多的東西,因為我們的傳輸路徑比傳統語音的傳輸路徑要簡單的多。我們不需要在音頻上做那麼多的預處理,來減少音頻的語調變化。我們只需要讓系統從相關數據中學習音調,從而能夠準確轉錄出語音信息。這種方法在普通話這種語言上很有效,並不需要改變輸入。
中文(普通話)另一個不同之處在於它的漢字系統。英語只有26個字母,而在中文中差不多有八萬個漢字。我們的系統在語音轉換的同時直接輸出漢字,所以我們認為和26個字母相比,每次在八萬個漢字中工作的難度非常大。我們用以克服這個挑戰的方法就是只使用漢字的一小部分,也就是人們的常用字。
Q:目前,百度已經開始在處理大量的語音檢索了。Deep Speech系統相比以前的普通話語音識別系統,好在哪裡?
Awni Hannun:百度的普通話語音檢索很活躍,而且效果不錯。我認為就所有的檢索活動而言,語音檢索仍舊只佔據很小一部分。我們希望讓這個比例變大一些,或者至少通過讓語音識別系統更準確,使人們更多地使用這個功能。

Q:你能描述一下像Deep Speech這種基於搜尋引擎的語音識別系統,和例如微軟的Skype語音實時翻譯系統(也是基於深度學習)的區別嗎?
Awni Hannun:通常,語音識別有三種模式。第一種是語音-轉錄模式;第二種是機器-翻譯模式;第三種是語音-合成模式。我們在談的,其實都是第一種語音-轉錄模式,我相信Skype翻譯的其中一部分是這種模式。
我們的系統和微軟那個系統不一樣的地方在於,我們的系統更多的是「端對端」。以前研發的語音檢索都有很多人為幹預:他們會看著系統,然後說哪些哪些特點很重要,或者系統應該要能夠預測某種音素。我們不一樣,我們只需要輸入數據,也就是一段音頻。對於一段WAV文件,我們幾乎不用進行預處理。然後我們有一個巨大的深度神經網絡可以直接轉錄輸出文字。我們輸入了足夠多的數據,所以在盡可能少的人為幹預下,系統得以辨別與輸入相關的資訊,並正確輸出轉錄結果。
最令我們驚喜的是我們並不需要過多地對其進行修改,除了給它設定範圍以及提供正確的數據。這個我們在去年12月展示的系統,在英語識別中做得非常好,中文識別也相當不錯。
Q:通常對於這種系統,從研發到生產需要多長時間?
Awni Hannun:這並不是一個簡單的過程,但我想不會比提高模型準確性更難——這更像是一個工程問題而不是研究問題。我們正在這方面積極努力,我們的研究系統很有希望在不遠的將來投入生產。
Q:百度在其他領域有一些計劃和產品,包括可穿戴設備,以及語音識別系統的其他嵌入形式。那麼你在做的工作和其他一些項目有關係嗎?
Awni Hannun:我們想要構建一個可以在智慧設備中充當介面的語音系統,而不僅僅是語音檢索。語音檢索在百度的整個生態中非常重要,所以這正是我們可以有重大影響的領域。

Baidu Eye:可穿戴電腦
讓深度學習模型無所不在
Q:目前深度學習的發展速度和重要成就,在你看來夠快嗎?
Awni Hannun:我認為現在深度學習的發展速度在加快,因為人們認識到當你輸入一些內容,並期待從電腦中獲得一些輸出的時候,你正在使用深度學習。如果是一些老的機器學習任務,例如機器翻譯或語音識別,這些是被人為重度幹預的。但是如果你嘗試用深度學習和數據來簡化整個路徑,就會得到顯著的成效。我們正處在這個的頂峰。
特別的,我們剛剛找出怎樣用深度學習處理接續的數據。我們做出了一個適配的模型,然後我們將開始簡化這個模型。當我們處理接續數據的時候,基線已經確定了。
超出這個範圍,我就不知道了。有可能我們會到達一個平穩期,也有可能我們會開始創造出一些新的東西來應對新的任務。我想這個故事的中心思想在於:「有大量數據的地方,以及可以使用深度學習模型的地方,成功極有可能發生。這就是為什麼人們感到深度學習發展速度之快的原因了。」
深度學習真的變成「我們怎樣獲取正確的數據」這個問題了。這才是真正的大挑戰。
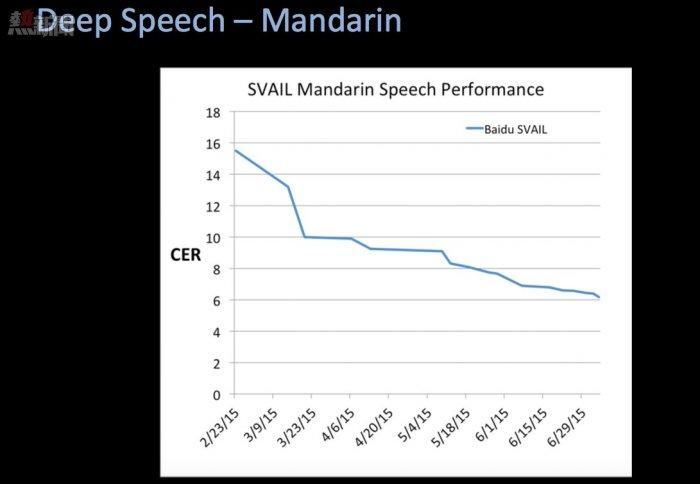
Q:從結構上來說,深度學習在一個強大的以GPU為基礎的系統上運行。有沒有可能將深度學習演算法移植到一個更小的系統,來減少百度服務器的運轉負荷呢?
Awni Hannun:這正是我在思考的問題。事實上,我覺得在這方面未來是光明的。確實,深度學習模型正在變得越來越大,但是模型的大小以及表達性在訓練過程中比在測試過程中更重要。
有很多事例可以證明以下這點:如果一個在32比特環境下訓練的模型,放到8比特的環境進行測試,運行效果一樣好(或者說差不多一樣好)。也就是說,大小可以縮小四倍,但運行起來同樣好。
同樣,我們在壓縮已有的模型方面也做出了很多努力。例如我們如何用一個已經吸收大量數據的巨型模型來訓練一個稍小一些的模型?而那個小模型可以嵌入到其他設備中。
通常,困難的部分在於訓練系統。在這些例子中,系統確實需要很大,而且服務器要穩固。但是我認為,現在有很多努力都可以將模型變得更小,而且未來有可能將其嵌入其他設備。
Q:搜尋引擎必須背靠雲服務,除非你可以把整個網絡裝載手機上,對嗎?
Awni Hannun:當然。這極具挑戰。
另外……
如果想要知道Deep Speech有多強大,以及百度為什麼這麼強調深度學習帶來的系統架構,你可以看看百度的系統研發科學家Bryan Catanzaro的解釋:
「正如其他深度神經網絡系統,我們的系統在接受越來越大的數據庫訓練後,變得越來越準確。中文擁有太多方言和地方口音,所以(百度)的研究員努力尋找大的數據庫,讓系統可以從中學習所有關於中文口語的細微差異。當我們集結所有這些數據庫之後,這種不斷擴展的訓練帶來了新的系統問題。
「為了給系統提供一些語境,我們完整的數據庫給Deep Speech進行一次訓練需要千億億次運算。每當評估一個新的網絡或新的數據會否改善Deep Speech,我們需要等待這個訓練過程的完成,這要好長一段時間。而相應的,我們越快訓練Deep Speech,我們就能評估得越多,整個系統也就進步得越快。
「這就是我們為什麼要特別關注訓練時發現的系統問題。當我們改善訓練系統的效率時,準確性的提高非常明顯。我們將系統訓練平行分置與多個GPU上,用來減少訓練的時間。在8個GPU上訓練一個模型時,我們的系統可以包含25兆運算,因此訓練Deep Speech的時間可以縮減到幾天。我們正在繼續突破系統擴展性的邊界,因為數據庫越拓展,準確率也就會不斷提高。」
From Medium
普通話語音檢索這個世界級難題,終於被百度解決了