





虎嗅注:2014年11月,Google研究院發表的一篇博文稱,未來Google的圖形識別引擎不僅僅能夠識別出照片的對象,還能夠對整個物理場景進行簡短而準確的描述,也就是「圖像識別神經網絡」(簡稱「神經元網絡」)。與Google對該技術進行研究的還有Facebook。近日,兩家公司先後透露了,各自對該項目有研究進展。本文綜合了網易科技、騰訊科技的相關編譯報道。
神經元網絡——人工大腦,其可以立即識別照片中人的面部、車輛、建築物以及其他對象。但是,該系統局限性仍存。
該網絡基於機器語言翻譯方面的研究成果:通過一種遞歸神經網絡(RNN)將一種語言的語句轉換成向量表達,並採用第二個RNN將向量表達轉換成目標語言的語句。

該網絡可以識別語音、將一種語言翻譯成另一種、定向投放廣告或者教會機械人開啟瓶蓋。如果將整個過程逆轉,人們可以讓該系統具備全新能力,不僅可以識別圖像,而且可以創造圖像。
Facebook表示,其正在教授自家的神經元網絡完成創建包括飛機、汽車及動物在內的圖像的任務,在40%的情況下,這些圖像足以讓我們相信自己看到的是真實照片。
而來自Google的研究人員則正在進行截然相反的工作,他們通過神經元網絡將真實的照片轉換成某種超現實主義的風格。他們讓機器識別照片中熟悉的模式,然後對這些模式進一步增強,然後在同一張照片中重複這一步驟。如果照片中的雲朵有點像鳥,網絡就會使其變得更像鳥一點,周而復始,直至完全體現出一隻鳥的樣子,其結果就是某種由神經元網絡生成的抽象藝術畫作。
以下是Google的實驗過程
研究人員將圖片輸入圖像識別神經網絡,並讓它識別該圖片中的一個特徵,並修改圖片以強調這項特徵。修改後的圖象然後被反饋到神經網絡,並讓神經網絡再次識別其他特徵並強調它們。最終,這幅圖片被修改得面目全非。
在一個低水準上,這種神經元網絡可以被用來檢測圖像的邊界。在這種情況下,這些圖像就像繪畫作品,使用過Photoshop濾鏡的人應該對此感到不陌生:

但是,如果神經元網絡被要求識別更複雜的圖像,——例如識別一頭動物,它會產生令人不安的奇幻圖景:

最終,這個軟件可以對隨機噪聲進行識別,但生成的結果完全屬於自身的想象:

如果你讓一個用來識別建築物的神經元網絡去識別一幅毫無特徵的圖像,它將產生這樣的結果:

這些照片是驚人的,但他們不僅僅是用來展示的。神經網絡具有機器學習的一個共同特徵:它不是向計算機輸入程式以讓它能夠識別特定的圖像,而是向它輸入許多圖像,並讓它自己整合這些圖像的關鍵特徵。
但是,這可能會導致軟件更加出人意料。我們很難知道軟件正在審查哪些特徵,以及它忽略了哪些特徵。例如,研究人員要神經元網絡在一幅隨機噪聲圖像中識別啞鈴,發現它認為啞鈴一定是有手臂握住的:
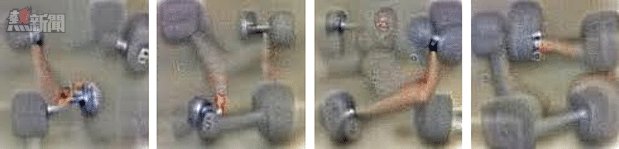
解決方案可能是向它輸入更多放在地上的啞鈴圖像,直到它明白手臂並非啞鈴的內在組成部分。
Google表示,通過將神經元網絡的運行過程逆轉,傳授它們生成圖像的技巧,能夠讓人們更好的理解它們的運作機理。Google讓網絡對自己在圖像中發現了什麼進行描述。有時,它們只是發現了某個形狀的邊界;有時,它們發現了更加複雜的事物,例如位於水準線上一座塔的輪廓或者一棵樹中隱藏的建築物。每一次,研究人員都能夠更好地理解該網絡。
雖然Facebook和Google在神經元網絡呈像效果上有所差異,但跨越了「多層」人工神經元還是能夠一致地完成特定任務。
通過該網絡,就特定層面的神經元是如何理解一副圖像的問題,人們可以獲得一個量化的答案,這幫助研究人員通過可視化方式來理解神經元網絡如何處理分類任務,進而改進網絡架構以及判斷是否網絡通過訓練完成了自我學習。
From 虎嗅
Google、Facebook研發的神經元網絡,如何進行場景識圖?











