





在寫這篇文章之前,我特意翻看了一下最近的微博。看到已經有人拿到了康夏的書,並且也收到了退款。那麼,至少,隨着時間推移,事情的真相會變得更清楚。
我之所以要寫這篇文章,其一是因為我和康夏有過兩封郵件,一通長電話的接觸,幫他做了發書和退款數據的基本整理;其二是因為,從我對Excel這個工具的理解和經驗,以及對數據長期的觀察,認為康夏賣書過程中間至少有一半的狀況是由數據引發,他的確被數據「坑」了;其三,原本過去也就過去了,大家都知道康夏最後選擇訣別社交網絡,但未來一定還會有個人甚至企業,會在社交網絡上發起有商品交易的互動行為,而數據,將決定事件走向「天堂」或「地獄」。
我希望把數據的經驗分享出來,以便發起人將來可以作為參考,參與者也更能理解事件的進程。而且,從我個人來講,以Excel數據狀況為事實,想要告訴大家,我們認為的康夏的某些錯誤,其實他真的無能為力,甚至,已經盡力。
我和康夏本是徹徹底底的陌生人,在這件事之前我沒有關注他的微博和公眾號,甚至不知道有這麼一個人存在。有一天,我看到朋友圈裡一位最近剛剛長聊過的,和我育兒理念非常相似,且相互認同的朋友,轉發了康夏收到77萬元時的第一篇說明文章。而我這位朋友在朋友圈表達的意思是,通過康夏賣書這件事,她發現有很多和她相同的讀書人,她很開心。出於對她個人品質的認可,我看完了那篇文章。當時腦子裡瞬間出現了兩個想法:一是,康夏表現的非常有誠意,是個不錯的人;另外,他一定會遭遇嚴重到他沒辦法解決的數據問題。由於我信任我這位朋友,愛屋及烏,再加上我的數據觀點一直是,原始數據對於數據工作有決定性作用。所以,既然是緣分讓我看到了這件事,我決定幫幫他。
我給他發去了一封郵件,說:「我對數據有些研究,覺得你可能馬上會面臨極大的數據難題。如果到時候需要幫助,就通過郵件聯繫我。」為了證明我是一個真實存在的人(沒辦法,互聯網上的信息真真假假),我還讓他上網搜搜,好確定我不是什麼騙子。我是5月19日給他發的郵件,5月20日,他的回覆是:「太感動了……非常感謝,已經快被海量數據搞死了。」
接下來的內容,是純技術性的,Excel用得稍好的人會理解得更清楚一些。如果你壓根兒不知道什麼是Vlookup函數,也沒有聽說過數據透視表,也不知道Excel中函數和數據處理的一般原則,那麼,這一段你可能無法比較有共鳴的感受到什麼叫「數據災難」。
康夏在後來的文章中反覆提到幾個東西:1萬條支付數據,一個人打款多次,做匹配很難,有的人信息填寫不全,支付寶限制20個字。一般人看到這樣的文字,都不會有特別的感受,但事實上,數據災難就藏在這裡面。他說的這張支付數據表,我給大家看看。(為了真實起見,我用的是康夏發給我的原始數據,但為了別人的隱私,我把與個人相關的關鍵數據做了類似遮擋、縮短等處理。我嘗試了把圖片另存下來,可以看到表格細節。)
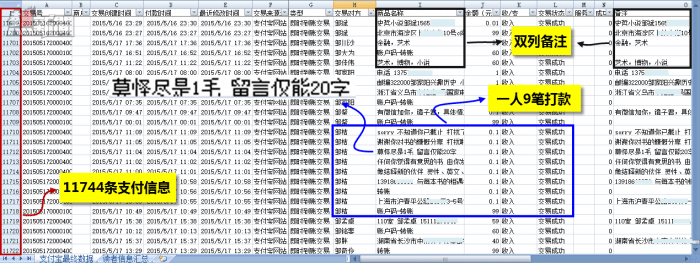
第一點——支付數據太多
這張表一共有11744條支付數據(截圖的時候往上挪動了一些,因為這部分數據更有代表性),若用肉眼看,手工整理,假設一條數據10秒,那也不是一般地球人體力和精力能承受的。在企業做過從系統中導出的這樣的表的人,就會很清楚其中的痛楚。所以,首先,數據量的確大到超出手工整理範圍了。我之所以強調手工,一是因為康夏告訴我他不怎麼會用Excel,二是我後面會講的,這份數據有先天的問題,函數等等只能給到輔助性的處理信息,而沒辦法真正批量得到最精準的結果。
第二點——支付數據先天有缺陷
表格中藍色框內的內容,體現了「支付寶限制20個字」以及「一個人多次打款」這兩件事。限制20個字帶來的嚴重後果,就是買家必須通過多次打款,每次留20個字,才能填寫清楚自己完整的地址以及對於書的喜好,甚至,還要給康夏留言,說兩句貼心話。而這件事給後期處理帶來的是什麼呢?
我們必須假設1萬條支付信息中,有名字相同的人,那麼,在發書和整理數據的時候,就要把名字相同的人挑出來。而由於一個人就可能形成了多條數據記錄,那麼,張三(1號)有10條數據(很多個0.1塊錢),張三(2號)有5條數據,Excel根本沒辦法知道,到底有幾個張三。傳統的「去重」方法不可行,用數據透視表計數的方法也不可行。而且,表格中其他數據,例如「交易號」、「交易創建時間」、「付款時間」等都不能用於輔助判斷,到底有多少重名的人。這就為後期的匹配埋下了嚴重隱患。
你可能會問:為什麼要匹配?匹配什麼?因為支付數據里,很多人一激動,根本沒留地址,甚至電話也沒有。那麼,康夏就沒有辦法給他們寄書,也不可能聯繫到他們(能力和精力都不行)。他就只能從自己的收集渠道,也就是他講的,公眾號、QQ、通訊錄、通訊地址上拔下來的,有地址和電話的,給他留言的買家中,用他們的信息再去支付大表裡進行匹配,看他們是否已經付款,以及付了多少錢,才能決定,應該給誰發書,發幾本。匹配的過程,雖然是Vlookup可以輕易做的,但這中間又有其他問題,所以,Vlookup的最終結果只能說湊合能用,這後面會講。
第三點——文本信息無法整理
表格中黑色框的部分,一個叫「商品名稱」,一個叫「備註」。我不知道買家在操作支付寶的時候是怎麼輸入的,但顯然,在一份原始數據中,有兩列文本描述的信息是極大的數據災難。因為,這兩列,有的人填的內容相同,有的人在兩列中內容互補,有的人填了其中一列而另外一列沒填,有的人把電話寫在「商品名稱」列,而有的寫在「備註」列。
Excel對於數據的判斷,是按屬性來的,例如:單元格填歷史、地理、天文這樣的代表科目的屬性詞。假如單元格內是一句話,要提取其中某個部分可就困難了。你可能說,不是有文本函數可以做嗎?對的,文本函數Right/Left/Mid/Search都可以做,但1萬行數據要有統一的規律才能批量處理。而像這張支付數據表,文本部分根本沒有任何規律可言,且分佈在兩列裡面。這是違反Excel數據結構規則的,所以,它幫不上忙。假設,文本只是分佈在兩列中,而同一個人的打款記錄只有一條數據,那麼,用&符號或者Concatenate函數,可以把兩部分文本合併到一個單元格,還有可能進行關鍵信息的提取。
但前面說過,張三可能有9條打款記錄,每一條備註了20個字,也就是說,不僅在行方向需要合併單元格內容,在列方向也要合併,這幾乎是不可能的。而提取不出支付數據中的關鍵文本信息,就相當於對買家的身份、聯繫方式、喜好等一無所知。也許還有人覺得,既然你康夏接了這個活兒,死也得用手工的方式,一條一條把數據對出來,這樣才對得起觀眾。
公平的講,姑且不說那段時間他有5000封郵件要處理,每分鐘微信都會留幾百條信息,還要打包,處理各種瑣事,就說啥事情也不做,只盯着數據看,一條核對30秒,中間不停,那也是一個時間上的天文數字。
親身體會數據,比從文字上看要殘酷得多
既然說到了工作量的問題,我覺得有必要多說兩句。我們平時看文章里寫維護10個微信群,一個人去了26個國家深度旅遊,或者800條數據要核對。這些數字往往看起來不太累,但真實做起來,卻要人命。羅輯思維二期會員招募的時候,一個死磕俠管理10個微信群,一個群幾百號人,一分鐘就會產生幾千條留言,而且每分鐘都在產生。你想想,讀完都不可能,怎麼在裡面回復。那時候,我親眼看見死磕俠們吐血地每天加班到凌晨甚至5點,那是一段回憶起來簡直血腥的日子。26個國家深度旅遊,看起來沒很多吧,但假設一年兩次選2個國家深度旅遊,26個國家需要13年。從17歲花季要干到30而立。800條數據核對看起來也不多,做做就知道了。
所以,從數據的角度,親身體會真的比文字上看到的要殘酷得多。有時候是儘力而為,但大多數時候是無能為力。
第二張表——康夏自己整理的買家信息

前面說了那麼多,想要證明的是,支付寶導出來的支付數據,由於有先天的缺陷,是無法用於做出發書或退款決定的(退款一會兒詳細講)。於是,康夏通過各種渠道,收集了2607條比較完整的買家信息。接下來,他就面臨要將這2607條數據(截止5月23日他給到我的),去到1萬條支付數據中進行匹配的工作。
匹配的目的是:第一,看這個買家真實體現在支付寶中的支付金額是多少?第二,看這個買家是否已經支付?前者,用於決定該寄出幾本書;後者,用於決定是不是要寄書。這時候,麻煩就來了。兩張表唯一可以進行匹配的只有「姓名」,在支付數據中叫做「交易對方」。姓名這件事很容易出問題,按照Vlookup的默認規則,只能匹配出第一條數據,當有相同名字的人存在於支付數據中時,Vlookup無法精確判斷誰和康夏收集的這個名字對應。這是處理后的數據可能不精準的第一原因。
匹配到對應的名字后,要通過Vlookup提取他/她具體支付的款項。由於支付數據中一個人可能打款9次,第一條記錄也許是0.1塊錢,這就不對。那麼,把支付數據中的金額先按降序排列,再匹配呢?也不行。因為,有的人是8個0.1塊,1個99塊,可以用99塊作為最終結果。而有的人是3個30塊,那麼,Vlookup只能匹配出其中一個30塊來,就產生極大的錯誤了。
假如先用數據透視表,按「交易對方」,也就是人名做金額的匯總后,再用Vlookup匹配,行不行?也不行。因為,在1萬條支付記錄中,我們根本不知道有幾個重名的人。數據透視表會把他們的金額加在一起,而這時候做出來的金額匹配,會出更大的問題。康夏有可能給張三(1號)寄去了6本書,但實際上,他只付了3本書的錢,而另外一個張三(2號)就會給了錢沒有收到書,後期還收不到退款,這事兒就鬧得更大了。
我想說這根本不是人乾的活兒,沒錯,進退兩難,有心無力。
各種數據缺陷下的折衷方案
從任何角度來講,我都沒有立場幫康夏決定應該寄書給誰。所以,我提供的僅僅是數據的初步整理和匹配,並且盡量給他更多的數據維度以便他做決定。同時,設定好退款清單的自動獲得,這件事很重要。至於那張表他最後是怎麼使用的,我也不得而知,能確定的是,這應該為他節約了至少一周的時間。兵荒馬亂中,能爭取到時間就很寶貴了,康夏自己在一篇文章中開心地說快了半個月,當然,後來都刪了。最終的寄書清單和退款清單,也許是從這張表來的。
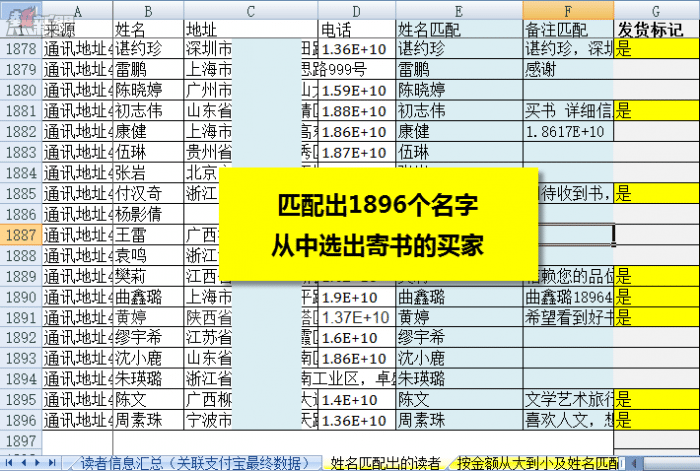
這張表用名字,從2607條完整的買家數據中,匹配出了已經支付的1896個買家,並且提取了一條對應的備註信息用於參考,以及與收集來的地址做可能的對照。
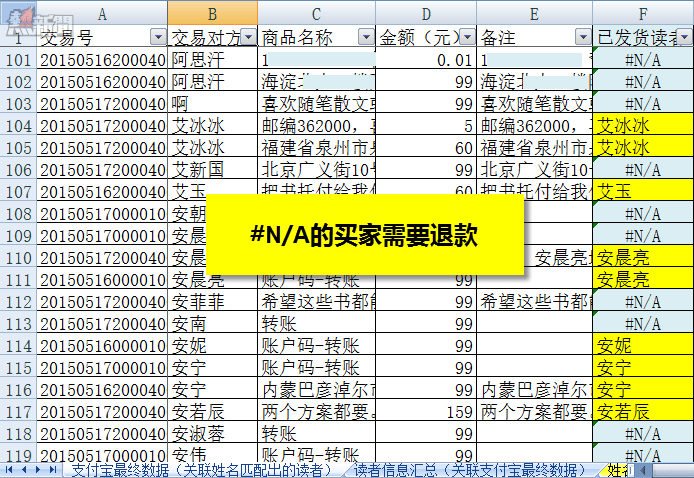
他要做的是,根據自己的判斷,從1896個買家中選出要寄書的人,在表格的「發貨標記」列選中「是」,這些數據就會返回到1萬條支付數據中,將對應的人標記出來。那麼,剩下的就是需要退款的買家清單。由於支付寶已經答應幫他做統一的退款,但清單需要他提供。所以,康夏必須先搞定所有的數據,把寄書的清單確定下來,甚至可能把書真實的寄了,才能給到支付寶一份最終的退款數據,退款這件事才能開始進行。
康夏在這件事上沒有撒謊,退款的確不是點一個按鈕就可以完成的,那麼多個0.1塊錢,假如他自己進行了一部分操作,後續數據的對應就更加難上加難,到時候場面會完全失控。
結語
過去的一段時間,很多文章從社交和互聯網方面,分析了康夏賣書事件演變過程中的種種原因和結果。孰是孰非,真相如何,我確定我自己也搞不清楚。就像有一篇文章說,對於一個事件,局外人就算以為自己知道了所有細節,其實也不知道其中真正的細節。
我不願意去揣測康夏的心思,但也沒辦法相信網絡上各方的言論,只是憑着自己原始的感受,以及有限的接觸,包括上面講到的數據災難。我會覺得,他並不可惡。真正要作惡的人,應該不會和自己的父母一起來干這件事,也許請臨時工會更好。對於即將留學的人,大部分都會至少準備半年吧,而臨到走之前,誰又會願意給自己惹一身事呢。再有,康夏也不是一個突然從石頭裡蹦出來的人,他之前在公眾號里的形象,對於關注他的人來說,也是認可才會參與到這個事件里來的。我是願意相信這裡面有信息不對稱所導致的誤會,也有一個人面對突髮網絡事件的措手不及,同時,在特定情況下腦子短路也許會做不當選擇的可能。
無論怎樣,一棒子打死一個人,否定他的所有過去,是沒必要的。而且,他在自己的公眾號和自己的粉絲玩了一件事,這點自由還是應該給他的。就像蔡康永在康熙來了有一集中,對黃國倫的建議:你家不收拾,只要你們夫妻倆自己受得了就行,其實,也不關別人的事。但是,以後倒也不用再把沒有收拾的照片拿出來嚇人。康夏賣書事件至此,至少,慢慢已經有人收到書,收到退款了。而康夏本人,因為這件事離開了社交網絡。一陣風起雲湧,終歸回到平靜。
祝福大家。
伍昊
于2015/6/13凌晨
From 伍昊
康夏散書事件的技術分析:在數據面前,他無能力為











