





▲從左開始: Terry Sejnowski, Cailey Bromer和Tom Bartol。
索爾克研究所發布的數據表明,人腦記憶容量可達到PB級別,相當於整個互聯網的數據量,這項研究也揭開了人腦高效節能之謎。發現也將有助於計算機科學家開發超精密的、高效節能的計算機,尤其是那些配置深度學習和人工神經網絡的機器,這些程序能夠勝任複雜的學習和分析,例如語音識別、圖像識別和翻譯。本文選自salk和CIFAR,機器之心編譯出品,參與:趙雲峰,微胖
來自索爾克的研究人員和合作者在神經元連接規模的研究方面取得關鍵進展,研究結果表明,人類大腦的記憶容量要遠遠高於常見的估計。這項新研究也解答了一個長期問題,人腦為何如此高效節能,這將有助於工程師去研發性能異常強大且非常節能的計算機。
「這在神經科學領域真的是令人震驚的事情,」索爾克研究所教授和這篇論文的聯合作者Terry Sejnowski說道,「海馬神經元擁有強大的計算能力且僅需要較小的能量,我們找到了解鎖它們設計原理的鑰匙。我們對人腦記憶容量進行了新的測量,其容量比我們通常保守的估計值提高了十倍,至少能達到1PB,與整個互聯網的信息容量相當。」
我們的記憶和思想是由大腦中的各種電化學活動模式所產生的。當像電線一樣的神經元分支在特定連接點(也就是突觸)相互作用時,就來到了神經元活動的關鍵環節。一個神經元的輸出「電線」(軸突)會連接到另一個神經元的輸入「電線」(樹突)上。信號借助被稱為神經遞質的化學物質在突觸間進行傳遞,來告訴接收神經元是否要將這個電信號傳遞給其他神經元。每個神經元都擁有成千上萬個突觸,每個突觸又連接着其他成千上萬個神經元。
「我們從海馬體中取出了相當於一個紅細胞大小的部分,當首次對裡面的每一個樹突、軸突、膠質和突觸進行重建時,突觸內部的複雜性和多樣性使我們有些不知所措,」論文聯合作者及得克薩斯大學神經科學教授Kristen Harris說,「儘管我之前希望能夠借助這些詳細的重建來弄清大腦如何組織的基本原理,但當對這份報告進行分析之後,我對大腦的精密程度驚嘆不已。」
突觸依然是個謎,儘管它們的功能紊亂會引發一系列的神經疾病。更大的突觸會擁有更多的表面積和包含神經遞質的泡狀體,它們會更強大,比起中小型突觸,它們更容易被激活。
索爾克研究所的團隊對老鼠的海馬體組織(大腦的記憶中樞)做了3D重建,他們注意到了一些不同尋常的現象。有時候,一個神經元的軸突會與另外一個神經元的樹突形成兩個突觸,這預示着第一個神經元好像又給接收神經元發送了一份副本信息。
研究者一開始沒有特別重視這累「雙重現象」,因為這在海馬體中出現的概率是10%。但索爾克的一位研究員Tom Bartol卻認為:如果他們能測量出這對相似突觸之間的差異,那他們就有可能深入了解突觸的尺寸,因為截至到目前為止,突觸還是僅僅依靠大、中、小來分類。
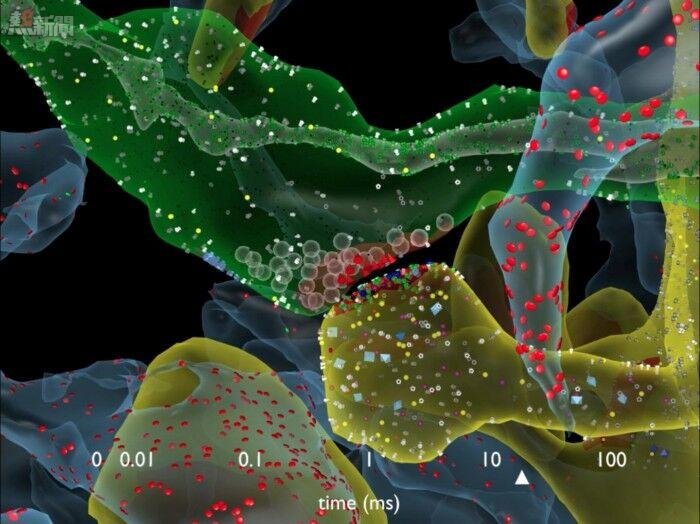
研究人員發現,實際上,這些突觸按照尺寸可以分成26類,而不是像之前那樣,只能分成大中小3類,每隔幾分鐘就會發生變化,也就是說,大腦有着強大得多的信息儲存能力。
在對大腦海馬體組織的虛擬創建中,索爾克和德克薩斯州大學奧斯汀分校的科學家們發現了這種不尋常的雙突觸現象。
為了完成這項任務,研究者使用了先進的顯微鏡和自己開發的算法來去老鼠的大腦進行成像,並從納米分子級別上模擬重建了神經元的連接、形狀、大腦組織的容量和表面積。
科學家團隊此前預計突觸的尺寸會大致類似,但非常奇怪地發現,所有的突觸幾乎完全一樣。Bartol說:「我們發現一對突觸的差異非常小,平均來說只有8%的差別,這讓我們非常吃驚。沒人想過它們的差異如此之小。但這就是大自然的刁鑽之作。」
由於神經元的記憶容量取決於突觸的大小,8%的差異成為一個關鍵數據,研究團隊可以將這個數據輸入到大腦的算法模型中,從而測量出突觸連接所擁有的潛在的信息存儲量。
以前大家一向認為最大的突觸和最小的突觸的差異範圍是一個60的參數,大部分都很小。但現在我們知道了,所有突觸的尺寸變化範圍是圍繞着8%,在60這個參數內,因此,這個研究團隊斷定,這些突觸按照尺寸可以分成26類,而不是像之前那樣,只能分成大中小3類。
「數據表明,現在突觸的尺寸類別比之前提高了10倍。」Bartol說。按照計算機術語,26中不同尺寸的突觸對應的信息存儲容量大約為4.7比特。先前大家的觀點是,大腦海馬體中短期記憶和長期記憶存儲容量只有1-2比特。
「大腦精度的數量級超出了此前所有人的想象,」Sejnowski說。這種精度令人疑惑的地方在於,海馬體突觸的不可靠眾所周知。當信號從一個神經元傳遞到另一個神經元,當時僅激活第二個神經元的10%-20%。
我們過去經常疑惑于,大腦非凡的精度是如何從如此不可靠的突觸中產生的?Bartol說。一個可能的答案是突觸持續的適應活動,久而久之會將它們的成功率和失敗率達到均衡。團隊借助這些新數據和統計模型去發現多少信號能使一對突觸抵消8%的差異。
研究者的計算結果表明,對於最小的突觸,1500個事件會使它們的大小發生改變(大約20分鐘),而對於最大的那些突觸,僅需要100個信號事件就能使其改變(大約1-2分鐘)。「這意味着,每隔2-20分鐘,你的突觸會向上或者向下變成下一個尺寸。突觸會根據它們接收到的信號進行自我調整。」Bartol說。
也就是說,大腦會以2-20分鐘為周期將突觸的尺寸調整到平均值。突觸越強大,它容易刺激下一個神經元。這26中不同尺寸的突觸和多餘的樹突結合起來,使大腦能夠在某一特定時刻優先設置神經網絡,使大腦消耗更低的能量,因此,當面對相同任務時,大腦的能耗要比計算機低。
「我們先前的研究暗示了通過突觸連接在一起的軸突和樹突會有着相同的尺寸,但大腦精度的事實着實引發了我們的注意,這為從一個全新的角度去思考大腦和計算機奠定了基礎,這項合作的研究成果為尋找大腦的學習和記憶機制開啟了新篇章。」Harris說。他補充道,研究結果給我們帶來了需要探索的新問題,比如說,這個規則是否適用於大腦其他區域的突觸,以及隨着突觸在學習早期階段的改變,這些規則將如何在發育過程中產生分化。
我們這項發現所帶來的影響意義深遠。Sejnowski補充到,看似混亂不堪的大腦內部其實隱藏着突觸精確的尺度和形狀,這些都隱藏了起來,不被我們所知。
這些發現也提供了一種對大腦令人驚訝的效率的有價值的解釋。成人在清醒時大腦只需要20瓦特的持續功率——這相當於一隻暗淡的燈泡所需要的耗能。索爾克研究所的發現也將有助於計算機科學家開發超精密的、高效節能的計算機,尤其是那些配置深度學習和人工神經網絡的機器,這些程序能夠勝任複雜的學習和分析,例如語音識別、圖像識別和翻譯。
Sejnowski說:「大腦的這個精妙之處毫無疑問的為我們提供了一種設計更好計算機的新方法,使用概率傳輸被證明是正確的,它需要較小的能耗,對於計算機和人腦都是如此。」「這是我們正在尋找的東西,」「隨着芯片添加越來越多的晶體管,它們也會有更多的瑕疵。」
現在,計算機記憶的一個失敗會導致整個系統功虧一簣。如果計算機能夠吸取人腦從冗余中受益的原理,每個人工突觸本質上是靠拋硬幣決定是否傳送信號,我們就能大幅度改善計算機能力。 Roland Memisevic 和 Yoshua Bengio已經開始探索這方面的可能性。
「Neural Networks with Few Multiplications」
摘要:眾所周知,大多數深度學習算法訓練非常耗費時間。既然訓練神經網絡過程中的大多數計算典型地將時間花在了浮點乘( floating point multiplications)上,我們研究出一種訓練方法,它能消除對所有這些的需要。
我們的方法由兩部分組成:
第一,隨機二進制化權重(binarize weights),將與計算隱藏狀態有關的乘轉換為符號改變(sign changes)。
第二,當BP誤差求導時,除了二進制化權重(binarizing the weights),我們量化了每一層表徵,將剩餘的乘轉換為二進制變化(binary shifts)。經由3個流行數據組(MNIST,CIFAR10,SVHN)的實驗結果表明,這一方法不僅沒有損傷分類表現,而且能取得比標準的隨機梯度下降訓練更好的表現,為快速、硬件友好的神經網絡訓練鋪平了道路。
作者:Zhouhan Lin, Matthieu Courbariaux, Roland Memisevic, Yoshua Bengio
Sejnowski說,「這是一個全新的計算機結構,最終會被用於開發新的芯片和操作系統,這一新系統不再以完美的、確定性數字計算機操作為基礎,而是建立在概率( probability)基礎上。」他補充說,訓練神經網絡能夠啟發我們如何研究大腦。「很有意思,我們研究已經發展到大腦理論正與計算機理論密切互動的程度。」
大腦記憶系統研究取得重大進展:或被用於開發新的芯片和操作系統











